Lieber Leserinnen, liebe Leser,
Heute möchte ich ein bisschen über Docker schreiben, nämlich über Sachen, die ich vor Kurzem in einem Online-Kurs darüber herausgefunden habe. Wie es viele Leser schon wissen, sind Docker und Kubernetes heutzutage sehr weitverbreitete Technologien, und deswegen möchte ich eine Kurzübersicht darüber teilen. Ich möchte es hervorheben, dass dieser Beitrag in keiner Weise komplett ist, aber hoffentlich kann das als eine Ermutigung für diejenigen Leute fungieren, die jetzt das Lernen von Docker nur überlegen. Los geht’s.
Einführung
Hypervisoren
Lasst uns erstmal die offensichtliche Sachen diskutieren, nämlich was Docker ist. Das ist eine Virtualisierungstechnologie, aber nicht im klassischen Sinn (wie es für Jahrzehnten bekannt war). Klassische Virtualisierungstechnologien verwenden einen Hypervisor, um Hardware zu emulieren. Das ermöglicht die Erstellung von angepassten Virtualmaschinen (mit verschiedenen Architekturen), die genauso wie echte Computer funktionieren. Es gibt zwei Hypervisor Typen: Typ-1, der direkt auf dem Harware läuft ((Xen, VMware ESXi, usw.), und Typ-2, der ein Hostbetriebssystem, auf dem es laufen kann, braucht (VirtualBox, VMware Player, usw.). Docker braucht dagegen keinen Hypervisor, sondern benutzt das Containers, um Software direkt auf dem Hostbetriebssystemkern auszuführen, und mittlerweile verwendet das die Einkapselungsmöglichkeiten des Kerns. Weil Docker sich auf Funktionen des Linuxkerns stark verlässt, um eingekapseltes Software von einander zu isolieren, bedeutet das, dass die Software mit dem Hostbetriebssystem kompatibel sein muss. In allen anderen Fällen braucht man einen Hypervisor (auf Windows-Machinen z.B. Hyper-V).
 Abbildung 1. Typ-1 vs Typ-2 Hypervisoren
Abbildung 1. Typ-1 vs Typ-2 Hypervisoren
Container vs VM
Aus erstem Blick sind die Unterschiede zwischen Container und Virtualmaschinen nicht so groß, also man könnte die Frage stellen: Warum wurde diese Container-Ansatz verbreiteter als traditionelle Virtualisierung geworden? Einer der Gründe ist, dass bevor die Softwareumgebung feingestimmt werden kann, ist die Installation und Konfigurierung eines ganzen Betriebssystems bei der hypervisorbasierten Virtualisierung für jeden Computer erforderlich. Obwohl vorgefertigte Betriebssystemabbildungen gemacht werden können, um dieses Problem zu vermeiden, eliminiert das den Bedarf für Systeminstandhaltung bei jeden Computer nicht (es gibt Automatisierungswekzeuge dafür, aber das ganze Verfahren ist nicht 100% bedienerlos). Es ist auch festzustellen, dass viele benutzte Software (auf der Betriebssystemebene) mit jeder Instanz vervielfacht ist, das, abgesehen von der erhöhte Wartungsoberfläche, mehr Speicherplatz braucht.
Hier kommen die Container im Spiel. Falls keine besonderen Anforderungen an dem Betriebssystem gestellt sind, kann die Software, die unsere Anwendung braucht, einfach gepackt und verbreitet werden, und mittlerweile wird der Rest der Software (Hardwareabstraktion, Scheduler, Initsystem, Kern, usw.) von dem Hostbetriebssystem durch Docker versorgt. Auf diese Weise gibt es nur eine Instanz des Betriebssystems, das Wartung braucht, und dieses System ist unter allen Containern geteilt.
 Abbildung 2. Klassische Virtualisierung vs Container
Abbildung 2. Klassische Virtualisierung vs Container
Wenn die Abstraktionsebenen unter die Lupe gestellt werden (Abb.3. verwischte Bereiche), wird man bemerken, dass man im vergleich zu einer hypervisorbasierte Virtualisierung (Abb.3. linke Seite), bei der alles außen des VMs abstrahiert ist, eine weitere Abstraktionsebene bekommt (Abb.3. rechte Seite), weil auch das Betriebssystem nicht mehr eine Sorge ist. Das ist ein bestimmter Schritt vorwärts, und das könnte einer der Gründe hinter der Popularität von Docker sein. An dieser Stelle müssen wir nur Docker auf ein beliebiges Betriebssystem installieren, und danach haben wir darüber keine Sorge, was genau außen Docker passiert (und wie Docker für uns als ein Dienst geboten wird), solange die vorgefertigte Arbeitsumgebungen (auf Dockersprache: image) heruntergeladen und bereitgestellt werden können.
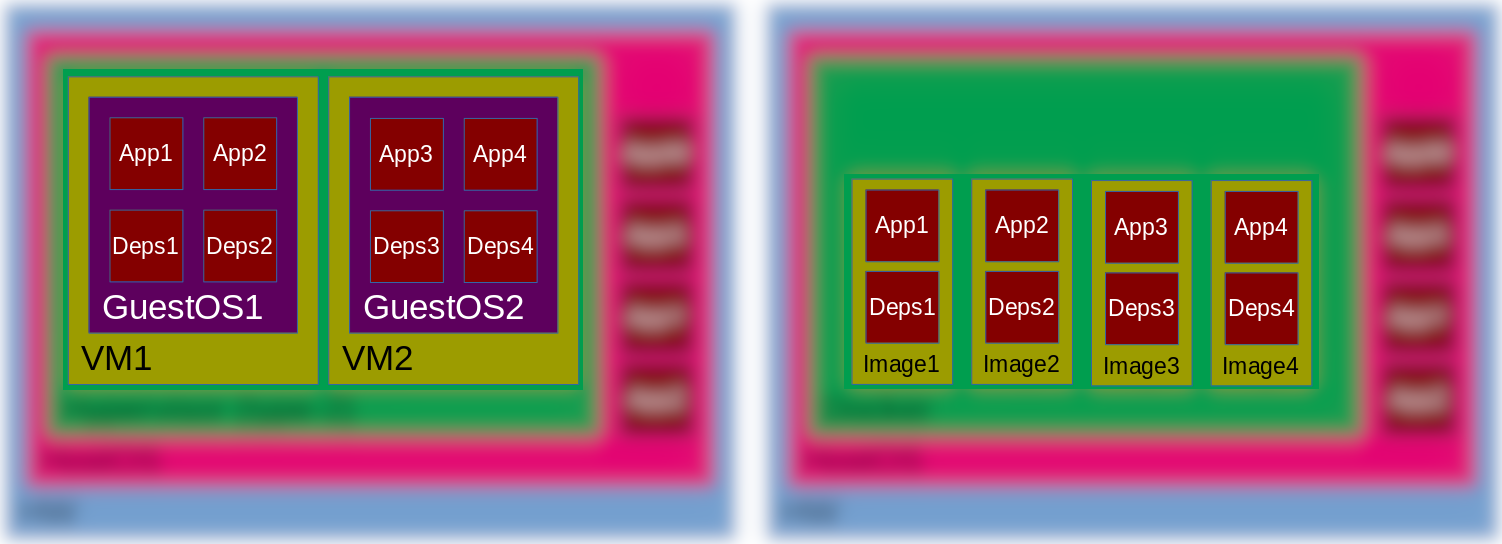 Abbildung 3. Abstraktionsebenen bei hypervisor- und containerbasierte Virtualisierung
Abbildung 3. Abstraktionsebenen bei hypervisor- und containerbasierte Virtualisierung
Docker
Docker image
Also, wie kann solche Image erstellt werden und was ist das eigentlich? Ein Docker-Image ähnelt sich einer live Linux-Abbildung, die z.B. auf einem USB-Stick ausgeführt wird, aber abgesehen von dem gewöhnlichen Unixverzeichnisbaum soll der Image nur diejenigen Abhängigkeiten enthalten, die unsere Anwendung wirklich braucht. Alle anderen Sachen werden von dem Hostsystem durch Docker versorgt werden. Auf diese Weise hat die Anwendung in diesem Image keine Ahnung, ob das ein Image oder ein echtes System ist, da alles gleich aussieht.
Wie erstellt man einen Image eigentlich? Einfach gesagt verwendet man frei zugängliche vorgefertigte Grundimages, um ein eigenes Image auf Basis des Grundimages mithilfe der eingebauten Dockerwerkzeuge zu bauen. Solche Grundimages können so klein wie ein paar MB (Alpine) sein, falls wir alle Abhängigkeiten selbst hinzufügen wollen; aber es gibt auch ausgereifter Images, die alle gewöhnlichen Grundabhängigkeiten (Node.js, PHP, nginx, CouchDB, usw.) sofort enthalten. Um zusätzliche Sachen zu vorhandenen Images einfach hinzufügen zu können, verwenden alle Images das UnionFS, das eine geschichtete und dokumentierte Aufbau eines Images ermöglicht. Jede Änderung erstellt eine neue schreibbare Schicht, indem die vorige Schicht lesbar wird, sobald die neue Schicht entsteht. Abb.4. stellt dieses Verfahren dar.
 Abbildung 4. Ein angepasstes Docker-Image schichtweise erstellen
Abbildung 4. Ein angepasstes Docker-Image schichtweise erstellen
Benutzerdefinierte Images erstellen
Die Erweiterung eines beliebigen Images wird mithilfe des Dockerfiles gemacht, der als eine Rezeptur für Docker für den Imagebau fungiert. Das beginnt am meistens mit einem FROM Befehl, der auf das zu nutzende Grundimage hinweist, dann (fast) jeder Befehl repräsentiert eine neue Schicht, zu der alle von den Befehlen bezeichneten Änderungen hinzugefügt werden. Solche Befehle sind COPY, ADD, usw, aber Umgebungsvariable oder geöffnete Ports können auch definiert werden. Interessanterweise, obwohl alle vorigen Schichten nur lesbar sind, ist es möglich, die Dateien dieser Schichten in einer neuen Schicht zu verändern, da jede neue Schicht nur ein Diff der vorigen Schicht repräsentiert. Das bedeutet, dass alle Änderungen der Images aufgezeichnet werden, und deswegen ist es einfach, früher gefertigte Schichten wiederzuverwenden oder das Image in eine diesen Schichten zurückzuversetzen. Zum Beispiel, wenn eine der Teilschichten verändert werden muss, sollte man nur den Befehl, der die ausgewählte Schicht repräsentiert, in dem Dockerfile bearbeiten. Nach den Änderungen wird dann Docker das Image erneut erstellen, indem alle nicht geänderten Teilschichten von Docker wieder verwendet werden.
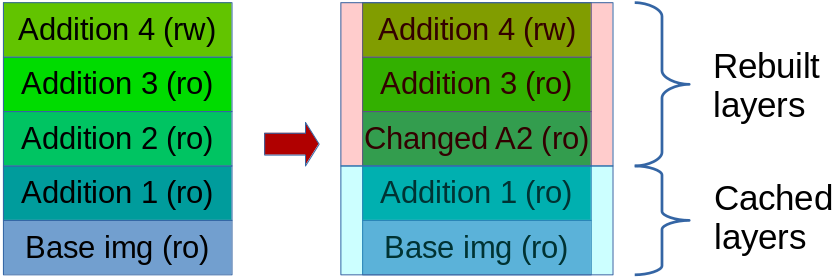 Abbildung 5. Veränderung der vorhandenen Images
Abbildung 5. Veränderung der vorhandenen Images
Images ausführen
Alle diese Sachen klingen gut, aber was passiert, wenn wir eine Anwendung, die das Dateisystem ändern muss, ausführen. Wird das unseres Image beschädigen? Sollen wir eine gesonderte Kopie des Images irgendwo speichern? Glücklicherweise nicht, da sobald die Anwendung ausgeführt wird, erstellt Docker auf der Image eine neue schreibbare Schicht, die von da an als ‘Container’ genannt wird. Alle Änderungen werden nur in diesem neuen ‘Container’ gemacht werden (siehe Abbildung unten).
 Abbildung 6. Anwendungen aus einem Image ausführen
Abbildung 6. Anwendungen aus einem Image ausführen
Das ermöglicht die Ausführung von mehreren Instanzen eines Images auch, da keine ausgeführte Instanzen können das Image verändern. Aber wird die neue ‘Container’-Schicht zwischen Instanzen geteilt? Die kurze Antwort ist nein. Eine längere Antwort ist nein, weil jede Instanz (oder ‘Container’) auf dem Image eine eigene neue Schicht erstellt, und jede Instanz kann seine eigene Änderungen in das Dateisystem schreiben (siehe Abbildung unten). Weiterhin, die Dateien, die während der Laufzeit nicht geändert wurden, werden zwischen alle Container geteilt. Auf diese Weise ist die Ausführung von mehreren Instanzen sehr Speichereffizient, da nur die Unterschiede von dem Image zusätzlicher Speicherplatz brauchen.
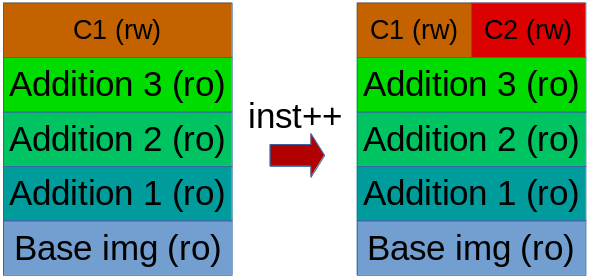 Abbildung 7. Mehrere unabhängige Instanzen einer Docker-Anwendung ausführen
Abbildung 7. Mehrere unabhängige Instanzen einer Docker-Anwendung ausführen
Persistente Daten speichern
Das klingt wunderbar, aber das soll ein bisschen überlegt werden. Was passiert, wenn das Image aktualisiert wird? Natürlich wird die Container-Schicht, die auf der vorigenen Version des Images erstellt wurde, mit dem neuen Image nicht mehr kompatibel sein, also die ganze Container-Schicht wird durch eine neue Schicht ersetzt werden. Das bedeutet, dass alle Änderungen (erzeugte Daten) verloren gehen. Deswegen ist nach allgemeiner Konsensus wünschenswert, die Container ephemer zu machen, oder anders ausgedrückt, so wegwerfbar zu machen, wie es möglich ist. Docker bietet mehrere Möglichkeiten, um die Daten außer Container zu speichern. Je nach Anforderung gibt es tmpfs mount für vorübergehende Daten, Bind mount für Datenzugriff auf ein Verzeichnis, das sich auf Hostdatensystem befindet, und Volumes für Hostunabhängige Datenspeicherung. Die Abbildung unten stellt alle Möglichkeiten dar.
 Abbildung 8. Typs von externen Datenspeicherung für Container
Abbildung 8. Typs von externen Datenspeicherung für Container
Jede hat natürlich Vorteile und Nachteile. Einige der Nachteile sind: tmpfs mounts sind nur verfügbar, wenn Docker auf Linux ausgeführt wird, und es ist nicht möglich, tmpfs zwischen den Containern zu teilen. Weil sich Bind-Mounts auf den Verzeichnisbaum des Betriebssystems verlassen, ist ein Image mit bind mounts nicht zu portable. Volumes brauchen Einzelverwaltung, da sie von den Containern unabhängig sind. Die Vorteile sind: tmpfs ist viel leistungsfähiger als die andere Ansätze. Mithilfe eines Bind-Mounts ist es möglich, Dateien, die sich auf Hostdatensystem befinden, im Container sehr einfach zugänglich zu machen. Volumes werden vom Docker verwaltet, deswegen wird die höhste Abstraktion auf der Systemebene gewährleistet (genauso wie es früher diskutiert wurde). Sowohl Bind-Mounts, als auch Volumes können mit mehreren Containern benutzt werden, um die gleichen persistenten Daten zwischen allen Container verfügbar zu machen.
Mehrere Container verwalten
Apropos mehrere Container, wie kann ein Nutzer alle oben diskutierte Sachen verwalten? Der Grundansatz ist die Nutzung des CLI und der folgenden Verwaltungsbefehle: docker container, docker image und docker volume. Jeder hat Unterbefehle wie create, rm, inspect, usw, mit der alles auf dem Host Schritt für Schritt eingestellt werden kann. Das sind für einfache Aufgaben geeignet, aber sie werden mit der Zunahme der Anzahl der Container, Volumes und Einstellungen langsam und mühsam. Mit dem CLI kann man bei einzelnen Maschinen die bisher gemachte Aufgaben aus den Augen einfach verlieren, weil nichts dokumentiert ist.
Aufmerksame Leser mögen schon an der Nutzung von Shell-Skripten gedacht haben, um die oben diskutierte CLI-Aufgaben zu automatisieren, und sie hätten Recht, wenn Docker immer noch auf Linux begrenzt wäre. Weil die Situation seit Jahren nicht so ist, müssten die Entwickler Dockers einen Ansatz ausklügeln, der von allen Kommandozeilen komplett unabhängig ist. Aus diesem Grund wurde Docker-compose ins Leben gerufen, ein Werkzeug, das alle obengenannte Sachen mithilfe einer docker-compose.yml YAML-Datei erledigen kann. In dieser Datei ist es möglich, mehrere Container und ihre Eigenschaften (Volumes, Ports, Netzwerke) für eine beliebige Anwendung einfach zu definieren. Das ist bestimmt ein Schritt voraus, da wir jetzt eine einfach lesbare und klare Dokumentation über die Anforderungen der Anwendung haben.
 Abbildung 9. Die gleiche Einrichtung mit Docker CLI und docker-compose erstellen
Abbildung 9. Die gleiche Einrichtung mit Docker CLI und docker-compose erstellen
Kommunikation zwischen den Containern
Nachdem wie mehrere Container einfach erstellen und einstellen können, könnte man die Frage stellen: wie sind sie verbunden? Container sind von Natur aus abgesondert, also wie kommunizieren sie zwischeneinander? Wie läuft der Netzwerkverkehr zwischen Host und Container? Die einfache Antwort ist: mit virtuellen Netzwerken. Docker bietet eingebaute virtuelle Netzwerke, und es gibt mehrere Typen: bridge, host, overlay und macvlan.
- Ein Bridge-Netzwerk (das Standardnetzwerk) bietet eine einfache Methode, verschiedene Container miteinander zu verbinden. Weiterhin ermöglicht dieses Netzwerk die Kommunikation mit dem Hostnetzwerk.
- Ein Host-Netzwerk entfernt die mittlere Ebene, deswegen können Container das Hostnetzwerk direkt benutzen.
- Ein Overlay-Netzwerk verbindet gesonderte Swarm-Dienste (mehr über das ein bisschen später) miteinander oder mit selbständigen Containern.
- Ein macvlan emuliert physikalische Netzwerkkarten durch die Einstellung von MAC-Addressen zu einem Container. Auf diese Weise scheint das Container ein echtes Netzwerkgerät zu sein.
Die Abbildung unten stellt eine mögliche Netzwerkeinrichtung dar, in der alle Typen von Docker-Netzwerke verwendet wurde.
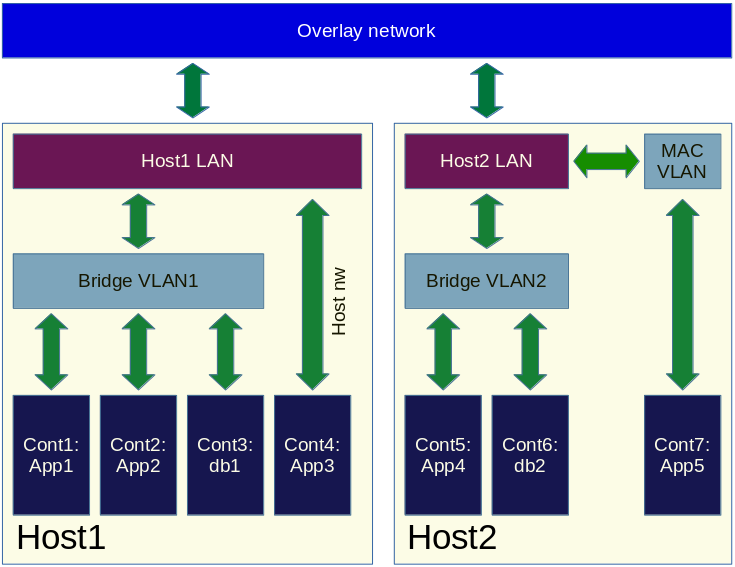 Abbildung 10. Vorhandene Netzwerktypen von Docker
Abbildung 10. Vorhandene Netzwerktypen von Docker
Docker Swarm
Scaling up
Als es früher diskutiert wurde, ist es einfach, mehrere Container mit docker-compose zu starten und einzurichten, aber das ist für Verteilungsaufgaben leider nicht geeignet, da das den Containerzustand nicht beobachtet, und es ist nicht einfach, die Last an mehreren Hosts damit zu verteilen. An dieser Stelle kommt Docker Swarm in Spiel, da das sowohl mit dem scale-up, als auch mit dem scale-out hilft. Lasst uns das peu à peu diskutieren.
Es wäre sehr gut, wenn unsere Anwendung nicht unerreichbar würde, wenn das Container aus irgendeinem Grund nicht mehr funktioniert. Eine einfache Lösung wäre, ein neues Container zu starten, wenn das letzte stirbt. Das ist eines der Merkmale von Swarm. Um das erledigen zu können, Swarm führt die folgenden Begriffe ein: Service und Task. Einfach gesagt ist ein Service eine Abstraktion einer abgekapselten Anwendung, hinter der die Arbeit durch Tasks gemacht wird. Ein Task ist eine Abstraktion eines Containers. Falls ein Container ausfällt, wird Swarm das gebrochene Container ablegen und ein neues in dem Task starten. Dieser Ansatz gewährleistet auch, dass die schon etablierte Verbindungen zwischen Containers im Hintergrund automatisch wiederherstellt werden.
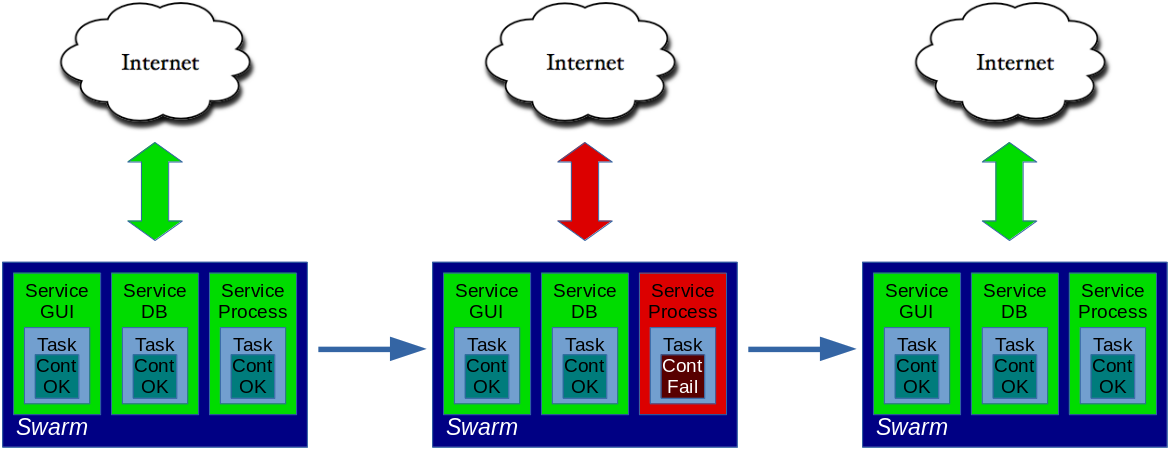 Abbildung 11. Docker swarm startet ein neues Task anstelle eines gebrochenen Tasks
Abbildung 11. Docker swarm startet ein neues Task anstelle eines gebrochenen Tasks
Das ist sehr gut, aber das ist nicht eine ideale Lösung wegen der kurzen Ausfallzeit, die existiert, bisher sich das neue Container startet. Um dieses Problem zu vermeiden, ermöglicht Swarm die Erstellung mehrere Repliken des gleichen Tasks innerhalb eines einzigen Services, also wenn eines der Tasks ausfällt, können die anderen Tasks die Anfragen weiter bedienen, und deswegen wird unsere Anwendung online bleiben.
 Abbildung 12. Durch die Erstellung von mehreren Repliken des gleichen Tasks innerhalb eines Services kann man die kontinuerliche Erreichbarkeit der Anwendung während Containerausfällen gewährleisten
Abbildung 12. Durch die Erstellung von mehreren Repliken des gleichen Tasks innerhalb eines Services kann man die kontinuerliche Erreichbarkeit der Anwendung während Containerausfällen gewährleisten
Scaling out
Bisher hat alles auf einem einzigen Host geschehen, das gut genug wäre, wenn es gewährleistet könnte, dass Hardware nie ausfällt und eine Ausschaltung wegen der Wartung nie erfordelich ist. Leider ist das nie so, also Swarm bietet weitere Möglichkeiten, um Hardware bezogene Problemen zu beseitigen. Solcher Begriff ist Node. Ein Node ist eine beliebige physikalische oder virtuelle Maschine (die eine eigene Docker-Installation hat), die mit dem gleichen Swarm verbunden ist. Es gibt zwei Typen von Nodes: Manager und Worker.
Ein Manager-Node ist für Empfang von Client-Befehlen, Task-Erstellung, IP-Addresse Zuteilung, Task-Zuordnung für Nodes, und Node-Verwaltung verantwortlich. Ein Worker-Node sucht nach neue Tasks und führt sie bei Erhalt aus. Um es besser zu verstehen, was jedes Typ von Nodes macht, stelle ich eine offizielle Docker-Abbildung vor:
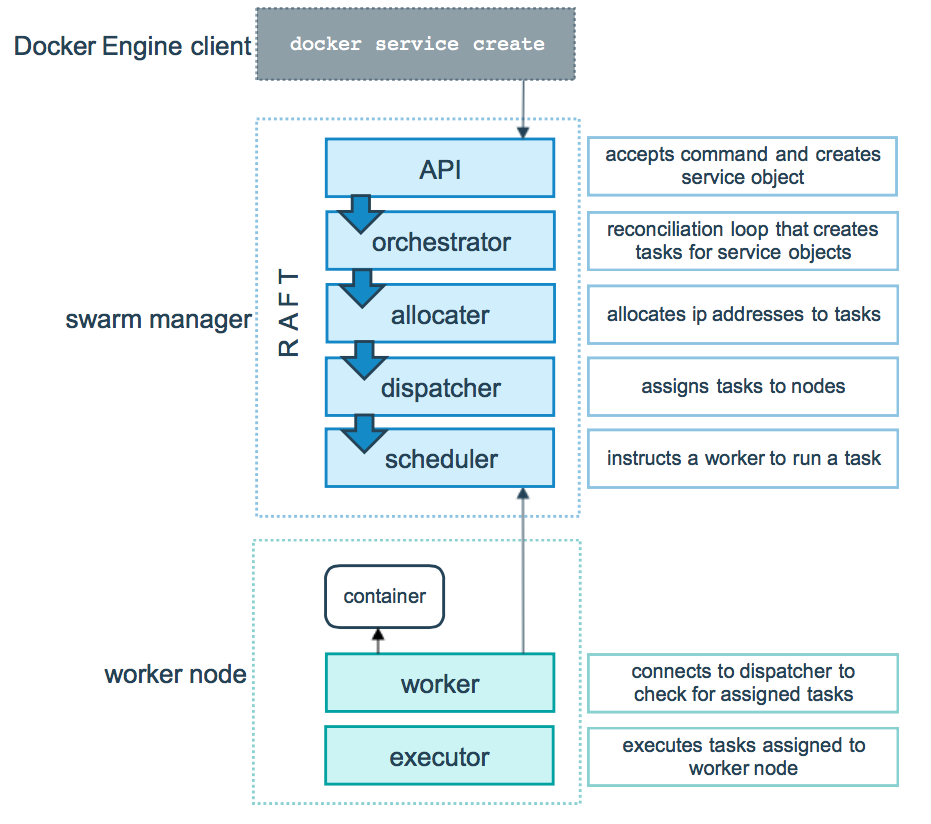 Abbildung .13. Manager- and Worker-Node Verantwortlichkeiten in einem Swarm (Offizielle Abbildung der Docker-Dokumentation)
Abbildung .13. Manager- and Worker-Node Verantwortlichkeiten in einem Swarm (Offizielle Abbildung der Docker-Dokumentation)
Obwohl die obene Abbildung stellt sehr gut dar, was jeder Node macht, ist das ein bisschen irreführend, da ein Manager-Node auch in der Lage ist, Tasks auszuführen. Tatsächlich machen sie das standardmäßig automatisch. Einfach gesagt haben wir jetzt ein Netzwerk von Maschinen mit unterschiedlichen Funktionen, aber es gibt eine Frage: wie werden Tasks unter diesen Nodes verbreitet? Um maximale Redundanz zu erreichen, verbreiten Manager-Nodes Taskinstanzen eines Dienstes (Service) an so viele Nodes, wie es möglich ist. Das nicht nur maximale Erreichbarkeit gewährleistet, sondern auch verwendet die Kraft von mehreren Harwareressourcen, um die Gesamtleistung zu erhöhen. Hier ist darüber eine Abbildung:
 Abbildung 14. Swarm verbreitet Serviceinstazen an mehreren Nodes
Abbildung 14. Swarm verbreitet Serviceinstazen an mehreren Nodes
Gewährlesiten, dass alles immer reibungslos funktioniert
An dieser Stelle ist es ganz offensichtlich, dass je mehr Nodes in einem Swarm teilnehmen, desto besser Erreichbarkeit erreichbar ist, nicht zuletzt die erhöhte Gesamtleistung. Aber was wäre, wenn ein Manager-Node ausfällt? Natürlich, die Anwendung wird unerreichbar, also um das zu vermeiden, beschränkt Swarm die Anzahl von Manager- oder Worker-Nodes innerhalb eines Swarms nicht. Tatsächlich, falls es nur wenige Nodes (z.B. 3) gibt, ist es empfehlenswert, alle Nodes für maximale Belastbarkeit als Manager zu erstellen. Weil es schon mehrere Managers mit komplett gleichen Fähigkeiten gibt, könnten die folgenden Fragen gestellt werden: Welcher Node macht die Entscheidungen, wenn eine Anfrage erhaltet wurde? Wie wissen die Nodes, wenn jemand die Anfragen schon erledigt hat?
Ohne in Einzelheiten zu verfallen, die einfache Antwort auf die erste Frage ist, dass es immer ein Leader manager gibt, der in einem Swarm für die Verwaltung von Tasks verantwortlich ist. Falls der Leader ausfällt, wird einer der anderen Managers die Rolle nehmen, dann wird der neue Leader die geforderte Tasks unter den verbleibenden Nodes verteilen. Lasst uns jetzt zu der zweiten Frage zurückkehren, nämlich wie die anderen Manager-Nodes wissen, ob sie etwas machen sollen. Mal wieder, nur einfach gesagt, alle Manager-Nodes teilen einen internen verteilten Statusspreicher, mit dem alle Manger-Nodes alle Swarm bezogene Sachen wissen. Mit diesem verteilen Status und dem Raft consensus Algorithmus sind sie in der Lage, den globalen Zustand des Swarms zu verwalten. Lasst mich eine offizielle Docker-Abbildung leihen, um das darzustellen:
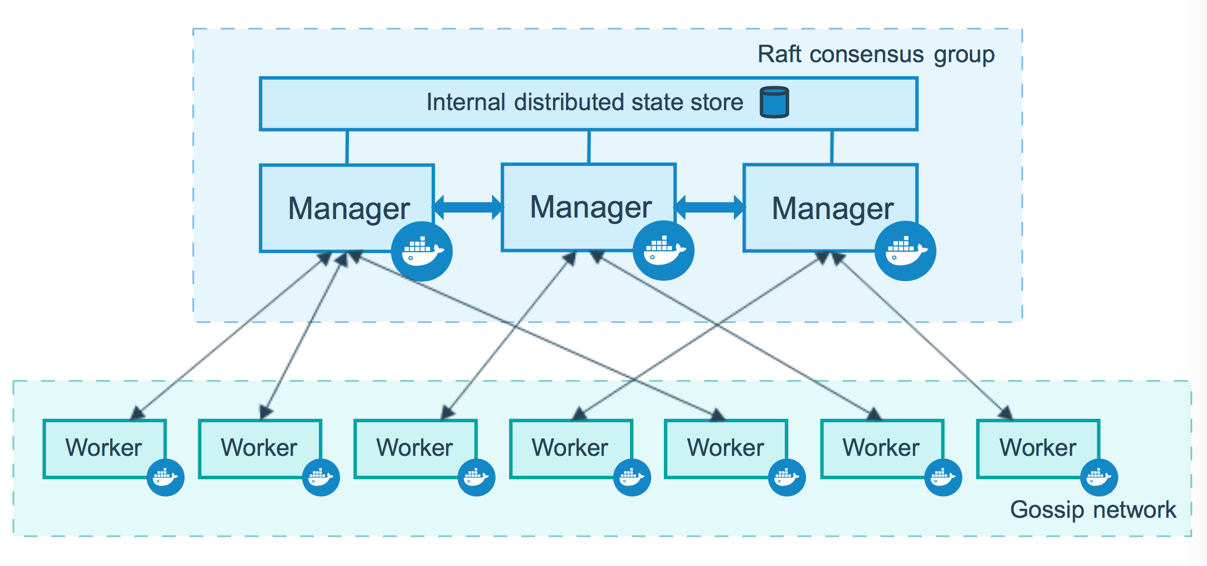 Abbildung 15. Mehrere Manager-Nodes teilen den Status des Swarms (Offizielle Abbildung der Docker-Dokumentation)
Abbildung 15. Mehrere Manager-Nodes teilen den Status des Swarms (Offizielle Abbildung der Docker-Dokumentation)
Swarm Netzwerke
An dieser Stelle könnte man sich Wundern, wie alle diese Sachen funktionieren? Wir haben mehrere Nodes mit mehreren Diensten, indem jener Dienst mehrere Instanzen hat, und alles funktioniert komplett transparent. Weiterhin, alle diese Sachen scheinen eine einzige Einheit zu sein. Die Antwort liegt (wie gewöhnlich) in Netzwerke. Wenn ein Swarm mit ein paar Diensten erstellt wird, wird ein neues Netzwerk für diesen Swarm auch erstellt. Tatsächlich, nicht nur ein neues Netzwerk wird erstellt, sondern zwei neue Netzwerke, und insgesamt braucht Swarm 3 Netzwerke, um einwandfrei zu funktionieren: ein overlay Netzwerk, ein docker_gwbridge Netzwerk und ein ingress Netzwerk.
- Das overlay Netzwerk gewährleistet die Kommunikation zwischen Dienste, die sich auf gesonderten Nodes befinden.
- Das docker_gwbridge Netzwerk verbindet overlay Netzwerke (einschließend ingress) zu dem physikalischen Netzwerk des Docker-Daemons.
- Das ingess Netzwerk behandelt Steuerungs- und Datenverkehr an Swarm Dienste.
Eine der interessantesten Merkmale dieser Einrichtung ist, dass der Dienst durch irgendeine IP-Addresse von verbundenen Nodes zugänglich ist. Das wird mithilfe des ingress Netzwerks und einigen Merkmals des Linuxkerns erledigt, das, einfach gesagt, ein Routing-Mesh erstellt. Eine viel detailliertere Erklärung von Swarm Netzwerke ist in der offiziellen Docker-Dokumentation oder in dieser ausgezeichneten tiefgründigen Analyse zu finden.
Ein Swarm verwalten
Genauso wie bei bloßen Container, alle Tätigkeiten können mithilfe der Kommandozeile und die Grundbefehle docker swarm, docker service und docker node behandelt werden. Leider hat dieser Ansatz die gleichen Schwächen wie die obengenannten Befehle für Container, also eine Lösung namens Stack, die sich an docker-compose ähnelt, wurde für Swarm auch gestaltet. Stack verwendet YAML-Dateien, die fast identisch zu der Compose-Dateien sind, als eine Rezeptur auch. Diese YAML-Dateien haben doch zusätzliche Merkmale, wie Replikanzahl, Einstellungen für Task-Neustart, Kontrolle für Dienstaktualisierung, Einstellungen für Task-Verteilung, usw. Die gute Sache ist über beide diesen Werkzeuge (compose und stack), dass sie mit der gleichen YAML-Datei arbeiten können. Das bedeutet, dass docker-compose in der Lage ist, die Anwendung lokal auf der Entwicklermaschine zu bauen und auf diese Maschine einzurichten, indem alle Swarm-Einrichtung bezogene Informationen ignoriert werden. Andererseits, Stack ist auch in der Lage, ein Swarm einzurichten, indem alle Build und lokale Einrichtung bezogene Informationen ignoriert werden. Infolgedessen braucht man nur eine einzige YAML-Datei für sowohl lokale Entwicklung, als auch für Ferneinrichtung zu warten.
 Abbildung 16. Die gleiche YAML-Datei für sowohl lokale Entwicklung, als auch für Ferneinrichtung verwenden
Abbildung 16. Die gleiche YAML-Datei für sowohl lokale Entwicklung, als auch für Ferneinrichtung verwenden
Sicherheit
Die letzte Frage ist Sicherheit. Man könnte einige sensiblen Daten wie Schlüssel, Zertifikaten, Passwörter, usw. benutzen, und es wäre gut, wenn diese Daten in die Anwendung nicht fest kodiert würden. Weiterhin, ein Swarm braucht viele Netzwerke, um funktionieren zu können, und einige dieser Netzwerke überqueren Node-Grenzen. Also, wie ist es möglich, die Daten während Datenverkehr und auf der Festplatte sicher zu halten? Erfreulich ist, dass alle Verwaltung bezogene Daten (und geteilter Status) während des Verkehrs standardmäßig verschlüsselt sind, und die Anwendungdaten auf dem Overlay-Netzwerk können auch verschlüsselt werden, wenn diese Möglichkeit benutzt ist (ein kleiner Leistungabfall ist dabei zu erwarten).
Auf der Seite der gespeicherten sensiblen Daten bietet Swarm Secrets, das ein Werkzeug für eine zentralisierte und verschlüsselte Datenverwaltung ist. Weiterhin bietet Swarm Möglichkeiten, diese gespeicherten sensiblen Daten nur für ausgewählte Dienste aufzudecken, um die kleinste Visibilität zu gewährleisten. Wie funktionert das denn? Einfach gesagt, ein Secret wird an einen Swarm-Manager geschickt, der die Daten auf eine verschlüsselte Weise speichert. Falls ein Dienst zu einem Secret Zugang hat, wird das entschlüsselte Geheimnis in das Container mithilfe eines In-Memory-Datensystems mountet, das die entschlüsselten sensiblen Daten enthält. Die gute Sache über diesen Ansatz ist, dass solche Daten aus dem Gesichtspunkt der Anwendung keine besondere Behandlung braucht, stattdessen können die Daten genauso wie mit gewöhnlichen Dateien normalerweise gelesen werden.
Zusammenfassung
Zusammenfassend kann ich sagen, dass Docker eine wirklich beeindruckende Technologie ist, weil das viele Probleme selbst zu lösen scheint. Wenn wir die anderen Merkmale Dockers auch in Betracht ziehen (context, logging, fortgeschrittene Sicherheit, Laufzeiteinstellungen für Harware-Ressourcen, usw.), die in diesem kurzen Übersicht nicht diskutiert wurden, ist es einfacher zu verstehen, warum Docker in einem so kurzen Zeitraum so beliebt wurde. Als es schon am Anfang dieses Beitrags erwähnt wurde, war diese Diskussion nicht zu tiefgründig. Falls Sie darüber mehr herausfinden wollen, empfehle ich die Absolvierung von Online-Kursen und/oder Konsultation der offiziellen Online-Dokumentation. Es wirklich lohnt sich.
Wie immer, vielen Dank fürs Lesen.