- Einführung
- Allgemeines Threading von C++
- Einfache Serialisierung
- Teilweise Serialisierung
- Andere Mutexe und Sperrungsmöglichkeiten
- Locks, mehrfache Sperrung der Mutexe, Deadlocks
Einführung
Liebe Leserinnen, liebe Leser,
dieses Mal werde ich über ein Thema diskutieren, das ich im Bereich Informatik wirklich mag: Leistung. Das soll keine Überraschung für jene sein, die ein bisschen mehr über C++ wissen, weil sich Leute, die diese Programmierungssprache lernen, über diese Sache in den meisten Fällen interessieren. Glücklicherweise, für alle C++ Enthusiasten nahm die Sprache im Bereich Leistung mithilfe der Veröffentlichung des C++11 Standards wieder zu. Diese Zunahme wurde durch eine offizielle Unterstüztung von Nebenläufigkeit und ein angemessenes Speichermodell und Bibliothek erreicht. Wenn die folgende Zusammenfassung über die Threading-Möglichkeiten des derzeitigen und zukünftigen Standards gelesen wird, wird es klar sein, dass die Relevanz des Themas nicht verringert hat, sondern wird es mit jeder Version wichtiger sein. Weil viele Bibliotheken eine Art von Threading verwenden (wenn auch das selbstimplementiert ist, wie z.B. bei Qt), ist es wichtig, eine Übersicht über die Theading-Möglichkeiten zu haben. Das ist der Grund des Schreibens dieses Beitrags. Los geht’s:
GEGENERKLÄRUNG: Weil ich nun über Nebenläufigkeit nur lerne, werden viele Erklärungen sehr einfach dargestellt, um die Möglichkeiten der Bibliothek einfacher zu verstehen. Ich versuche mich hier in die Details nicht zu vertiefen (oder über die Grundlagen von Threading zu diskutieren), weil darüber ausgezeichnete Bücher zur Verfügung stehen, wie z.B. das vor Kurzem veröffentlichte “C++ Concurrency in Action” (2. Auflage) von Anthony Williams, das ich als die Grundlage dieses Beitrags verwende. Wegen der Vorhandensein von Bücher und des ungeheuren Ausmaß des Themas werde ich mich auf C++ Threading-Bibliothek bezogene Sachen beschränken, deswegen ist eine Vorkenntnis darüber erwartet. Um viel mehr Einzelheiten darüber zu lesen, befragen Sie bitte das obengenannte (oder ein beliebiges anderes) Buch.
Weiterhin, falls Sie manche Fehler finden oder Vorschläge haben, schicken Sie mir sie bitte. Alle Beiträge sind willkommen.
Allgemeines Threading von C++
Eine der vielen Threading-Möglichkeiten von C++, die einfach zu begreifen ist, ist std::thread. Man könnte daran denken, wie ein Objekt für Threads, das nur einen einzigen Thread enthalten kann. Weil es ein Objekt ist, gelten dafür alle gewöhnlichen Einzelheiten von anderen Objekten weiter, wie z.B.: Lebensdauer, Verschiebbarkeit, Klassenfunktionen, Klassenvariablen, usw., also dieses Objekt braucht eine besonderere Behandlung nicht. Hier ist es im Einsatz:
 Abbildung 1: Ein Hauptthread startet zwei Kindthreads, dann wartet es auf sie.
Abbildung 1: Ein Hauptthread startet zwei Kindthreads, dann wartet es auf sie.
In diesem Beispiel führt das Hauptthread zuerst zwei gesonderte Threads aus, t1 und t2, dann setzt es sich mit den eigenen Sachen fort, bis eine join() Funktion aus den anderen Threads aufgerufen wird. Diese Funktionen sind Punkte in einem Programm, bei denen sich das Hauptthread mit allen anderen Threads wieder vereinigt (daher der Name join). Das bedeutet, dass an der einen oder anderen Stelle der Aufruf von join() für alle Threads unbedingt notwendig ist. Aufmerksame Leser konnten das schon bemerken, dass es eine Lücke zwischen den join()s der zusätzlichen Threads gibt, die nicht ein Zufall ist. Das stellt eine sehr wichtige Eigenschaft von join() dar: wenn ein ausgeführter Thread (Thread #3) seine Arbeit (die bis den Aufruf von join() aufgestapelt war) nur nach der Arbeit des Hauptthreads beendet, wird das Hauptthread auf den Kind-Thread warten (und gar nichts machen). Falls der Kind-Thread (Thread #2) seine Arbeit vor der zugehörigen Aufruf von join() beendet, wird das Hauptthread weiterarbeiten. Natürlich könnte solche Thread-Verwaltung nicht immer geeignet sein, also ein unterschiedlicher Ansatz steht zur Verfügung auch:
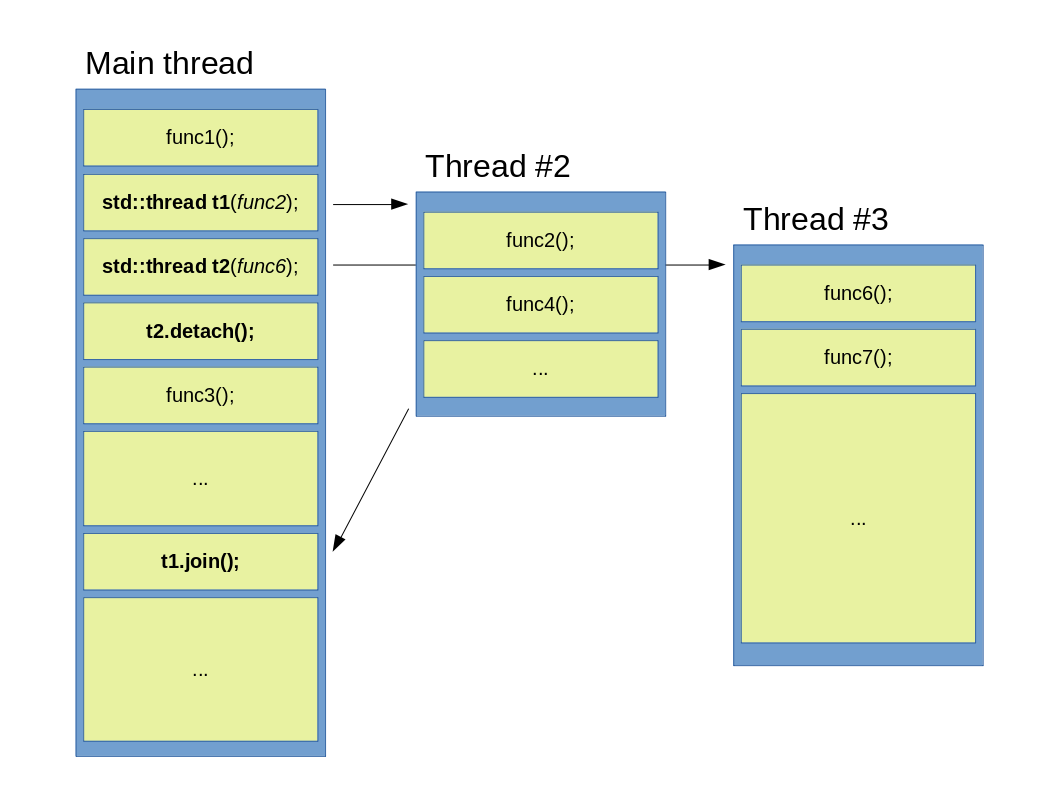 Abbildung 2: Ein Hauptthread startet zwei Kindthreads, dann wartet es nur auf einen.
Abbildung 2: Ein Hauptthread startet zwei Kindthreads, dann wartet es nur auf einen.
Dieses Beispiel illustriert ein anderes Szenario. Das Hauptthread startet immer noch zwei Kindthreads, aber nachdem t2 erstellt wurde, wird auch detach() sofort aufgerufen. Der Aufruf von detach() bedeutet, dass sich das Hauptthread nicht mehr über die Sachen des Kindthreads interessiert, und von da an hat t2 sein eigenes abgesondertes Leben. Die fehlende Lücke zwischen den Aufgaben und der fehlende Pfeil zwischen den Threads zeigt dieses Szenario. Ein wichtiger Unterschied ist, dass obwohl ein normales Thread von dem Hauptthread durch ein std::thread Objekt kontrolliert und besitzt ist, wird die Kontrolle und der Besitz des abkoppelten Thread auf der C++ Laufzeitbibliothek übertragen. Diese Übertragung ist auch unwiderruflich. Das bedeutet, dass nach der Abkoppelung des Threads gibt es keine Weise, durch die der Thread zurückgefordert werden kann, und das std::thread Objekt gilt von da an als lehr, und es ist bereit für Wiedereinsatz oder Zerstörung. Ob ein std::thread Objekt mit einem echten Thread verbunden ist, kann man es mithilfe der joinable() Funktion überprüfen. Solche abgekoppelten Threads sind als Deamon-Threads bekannt.
Einfache Serialisierung
Es gibt viele Fälle, wenn die Ausführung von komplett abgesonderte Threads nicht möglich ist, sondern müssen Daten zwischen diesen Threads getauscht werden. Solche gleichzeitigen Zugriffe auf änderbare Daten können wegen Data Race problematisch sein, die zu einem undefinierten Verhalten führen. Um diese Situationen zu vermeiden und einen sicheren Zugriff auf solche Daten zu ermöglichen, bietet die C++ Thread-Bibliothek etliche Klassen. Bemerken Sie bitte hier das Wort ‘änderbare’, weil ein gleichzeitiger Zugriff auf schreibgeschützte Daten am meistens solche Probleme nicht erzeugen. Die allgemeinste Lösung der derzeitigen Schutzmöglichkeiten ist vielleicht der std::mutex, an den man als eine besondere bool Typ denken kann, weil das auch nur zwei Zustände hat: gesperrt und ungesperrt. Der großte Unterschied (aber nicht der einzige) zwischen einem gewöhnlichen bool und einem Mutex ist, dass gleichzeitig nur ein einziger Thread in der Lage ist, den Mutex zu sperren (anders gesagt den Zustand zu ändern). Das bedeutet, dass alle anderen Threads, die lock() auf einen gesperrten Mutex aufrufen, auf die Entsperrung des Mutexes warten müssen. Die Sperrung des Mutexes ist auch eine atomare Operation. Das bedeutet, dass die Änderung des Mutexzustands aus dem Gesichtspunkt der Außenwelt (aka andere Threads) unmittelbar ist, oder anders ausgedrückt, hat die Änderung keinen Zwischenzustand.
Der Zweck eines Mutexes ist die Sperrung des Zugriffs auf den Code (und damit auf Daten) für Threads, die den Mutex nicht gesperrt haben. Das gewährleistet, dass der geschützte Code nur von einem einzelnen Thread gleichzeitig ausgeführt wird (Schaubild unten).
 Abbildung 3: Ein Mutex blockiert die gleichzeitige Ausführung des geschützten Codes.
Abbildung 3: Ein Mutex blockiert die gleichzeitige Ausführung des geschützten Codes.
Wie es oben offensichtlich ist, sperrt Thread ‘A’ den Mutex, und danach kann der geschützte Code von diesem Thread sofort ausgeführt werden. Thread ‘B’ und ‘C’ rufen die lock() Funktion ein bisschen später auf, aber weil der Mutex von Thread ‘A’ schon abgesperrt ist, müssen diese andere Threads auf den Aufruf von unlock() warten. Nachdem Mutex m entsperrt wurde, sperrt Thread ‘B’ den Mutex, und dann führt B den gleichen geschützten Code aus. Letztendlich entsperrt B den Mutex, um ein Zugriff auf den gleichen Code für C zu ermöglichen. Weil mit dem geschützten Code nur ein einziger Thread gleichzeitig arbeiten kann, und alle anderen Threads damit nur nacheinander arbeiten können, ist diese Methode auch als Serialisierung genannt, weil keine parallele Ausführung stattfinden kann. Es kann auf unterschiedliche Art und Weise dargestellt werden. Zwei solche Darstellungen sind unten zu sehen. Das erste Schaubild zeigt zwei Fläsche, die an der Flaschenmündung gekoppelt sind, und die Mündung enthält den von dem Mutex geschützten Code. Bei der Mündung ist nur seriale Ausführung möglich.
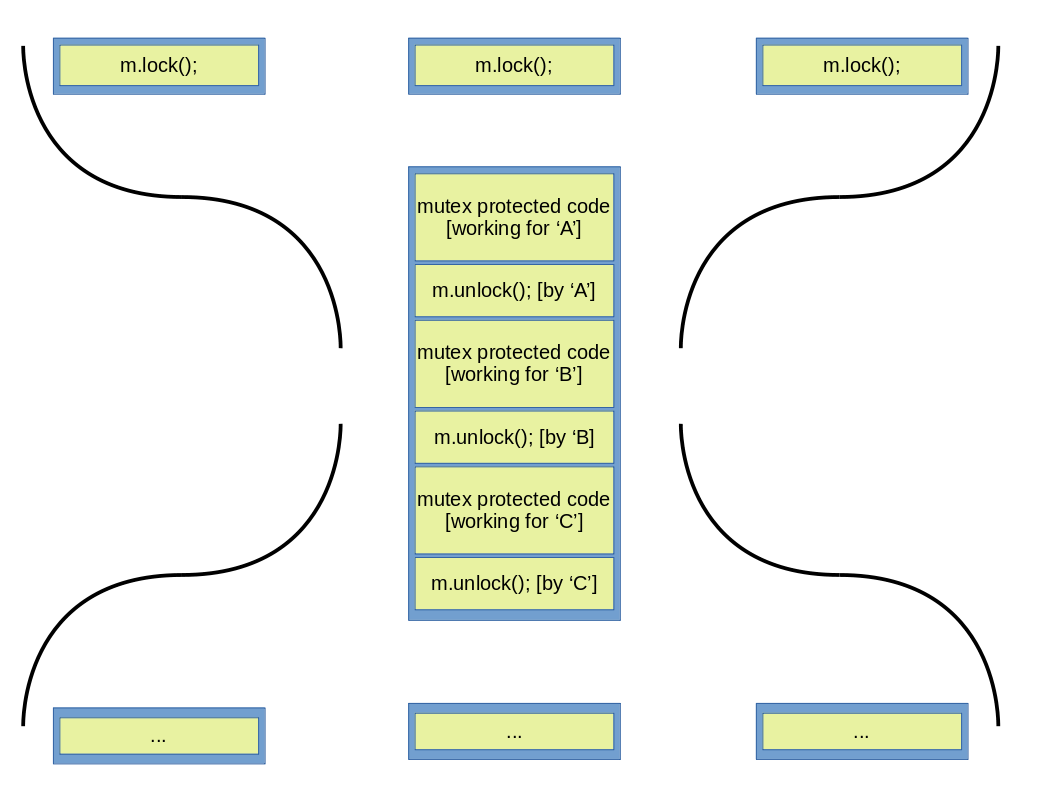 Abbildung 4: Serialisierung abgebildet mit dem ‘gekoppelte Flasche’ Schema.
Abbildung 4: Serialisierung abgebildet mit dem ‘gekoppelte Flasche’ Schema.
Das zweite Schaubild zeigt einen ausgeführten ‘virtuellen Serialisierungs-Thread’, der die Fortsetzung der anderen Threads bis den Aufruf der entsprechenden unlock-Funktion nicht erlaubt. Das ist wichtig zu bemerken, dass keine neuen echten Threads gestartet werden, daher ist das als ‘virtual’ genannt.
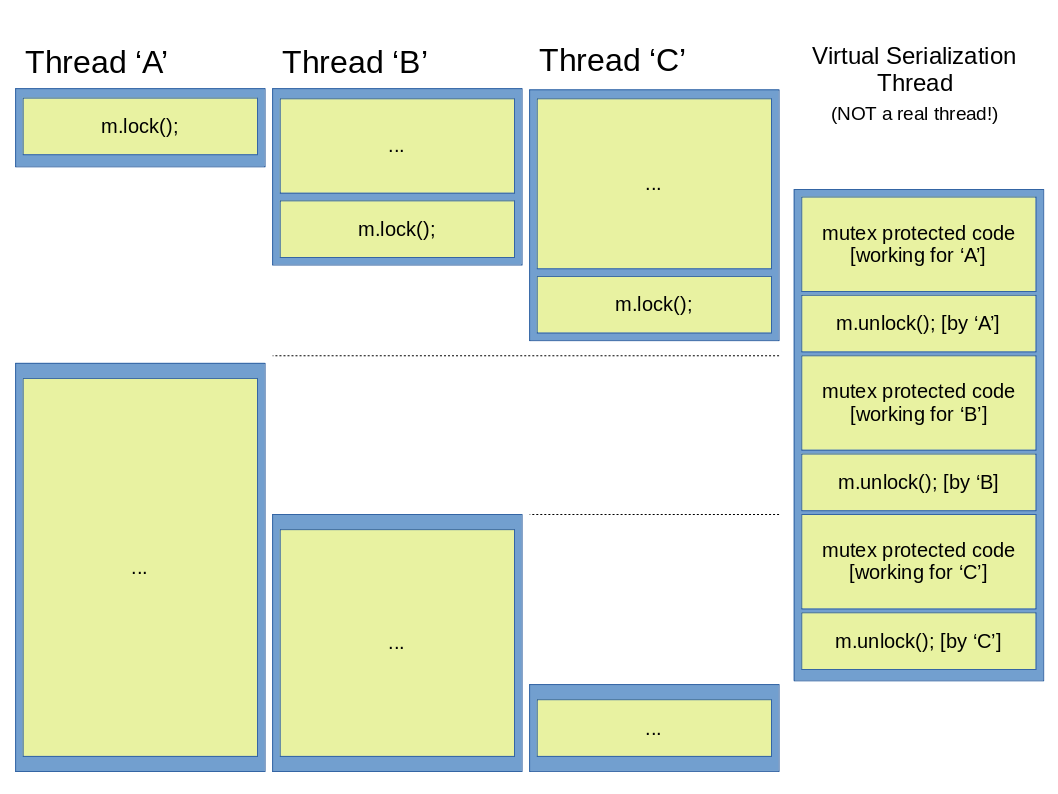 Abbildung 5: Serialisierung abgebildet mit dem ‘virtualler Thread’ Schema.
Abbildung 5: Serialisierung abgebildet mit dem ‘virtualler Thread’ Schema.
Es ist zu beachten, dass die Schaubilder oben nur ein vereinfachtes Ausführungsmuster zeigen, weil es dank der C++ Speichermodell in der Wirklichkeit keine Garantie gibt, dass den Mutex aus den zwei wartenden Threads ‘B’ vor ‘C’ sperren wird, wenn auch lock() von ‘B’ vor ‘C’ aufgerufen wurde (das obengenannte Buch enthält viel mehr Einzelheiten darüber).
Teilweise Serialisierung
Das Schema oben kann natürlich für manche Zwecke zu einschränkend sein, weil es Fälle geben können, in denen die geschützten Daten nur Thread ‘A’ modifizieren will, aber Threads ‘B’ und ‘C’ wollen die Daten nur lesen. Als es schon erwähnt wurde, sind solche gleichzeitigen Lesen ohne negative Auswirkungen erlaubt. Das bedeutet, dass die Verzögerung des ‘C’-Threads in diesen Fällen komplett unnötig ist, also das unten zu sehende Ausführungsmuster wäre bevorzugt.
 Abbildung 6: Eine erwünschte und verbesserte Ausführungsmuster, wenn ‘B’ und ‘C’ die Daten nur lesen wollen.
Abbildung 6: Eine erwünschte und verbesserte Ausführungsmuster, wenn ‘B’ und ‘C’ die Daten nur lesen wollen.
Dieses Ausführungsmuster könnte als teilweise Serialisierung genannt werden, weil Serialisierung nicht in allen Fällen gescheht, sondern nur in einigen gewünschten Fällen. Als es sich herausstellte, ist dieses Ausführungsmuster durch die Nutzung von Mutexe, die mehr Funkionalität als ein schlichter std::mutex anbieten, erreichbar. Zum Beispiel, wenn ein std::shared_mutex oder ein std::shared_timed_mutex zusammen mit einem std::unique_lock oder std::shrared_lock verwendet ist, könnte man die obengenannte Sache erreichen. Bevor über Einzelheiten diskutiert werden, gibt es einige erwähnenswerte Sachen. Eine dieser Sachen ist die Ähnlichkeit zwischen den Mutexen und der Nutzung des new-Operators für die Erstellung von neuen Objekten. In beide Fällen ist der Programmierer für die Verwaltung verantwortlich. Das bedeutet, dass der Programmierer nach dem Aufruf der lock()-Funktion sicherstellen soll, dass unlock() später in dem Code auch aufgerufen wird, oder andere Threads werden unbegrenzt blockiert werden. Das ähnelt sich dem delete-Operator, den nach der Erstellung eines durch den new-Operator erstellten Objekts aufgerufen werden soll, sonst wird das zu einem Speicherleck führen. Es gibt auch andere Ähnlichkeiten: wenn lock() und unlock() mehr als einmal an einem std::mutex aus dem gleichen Thread aufgerufen wird, wird das zu einem undefinierten Verhalten führen, genauso wie bei dem zweimaligen Aufruf von delete an dem gleichen Heap-Objekt.
 Abbildung 7: Ähnlichkeiten zwischen new/delete und lock()/unlock()
Abbildung 7: Ähnlichkeiten zwischen new/delete und lock()/unlock()
Um die obengenannten Probleme zu vermeiden, kann das RAII idiom verwendet werden (mal wieder, genauso wie bei new/delete), aber im Falle der Mutexe sollten Lock-Guards benutzt werden, wie z.B.: std::lock_guard. Der Zweck von Lock-Guards ist die Gewährleistung eines Bereichlebensdauers für die Sperrung/Entsperrung von Mutexe, damit wenn der Lock-Guard den Scope verlässt, wird es den Mutex durch seinen Destruktor entsperren. Das nicht nur eine begrenzte (und automatische) Lebensdauer für die Sperrung garantiert, sondern auch die mehrfache Sperrung/Entsperrung des Mutexes.
Nach der kurzen Einführung von Locks kehren wir zu dem verbesserten Ausführungsmuster der Abbildung 6 zurück. Durch die Nutzung von einem std::shared_mutex oder std::shared_timed_mutex ist es möglich, einen sogenannten Leser-Schreibermutex zu erstellen. Der Unterschied zwischen einem std::shared_mutex / std::shared_timed_mutex und einem schlichten std::mutex ist, dass eine mehrfache Sperrung erlaubt ist, falls sie mit den geeigneten Locks (std::lock_guard / std::unique_lock und std::shared_lock) verwendet sind. Wenn ein std::shared_mutex durch einen std::unique_lock gesperrt wird, wird der Thread, der diesen Lock bunutzt, einen exklusiven Zugriff auf den geschützten Code haben, und deswegen ist eine parallele Ausführung nicht mehr möglich. Das ist erforderlich, wenn die Invarianten des geschützten Codes vorübergehend gebrochen müssen (z.B.: während der Hinzufügung eines Elements zu einer Datenstruktur). Falls die Invarianten einer Funktion nicht gebrochen werden müssen (z.B. Lesen), kann ein std::shared_lock verwendet werden, weil dieser Art von Locks die Sperrung des Mutexes (die mehrfache Sperrung unterstützen) aus mehreren Threads erlaubt. Es ermöglicht nicht nur einen Zugriff auf den geschützten Code aus mehreren Threads, sondern auch eine echte Nebenläufigkeit. Das ist wichtig zu bemerken, dass ungeachtet des benutzten Mutexes ein std::unique_lock oder std::lock_guard die Sperrung aus mehreren Threads nicht erlauben. Deswegen, solange ein std::shared_lock einen Mutex (der mehrfache Sperrung erlaubt) benutzt, wird std::unique_lock den Mutex nicht sperren.
Andere Mutexe und Sperrungsmöglichkeiten
Einer der Mutexe, der noch nicht erwähnt wurde, ist der std::recursive_mutex, an den man als der Gegenteil des std::shrared_mutex denken kann: obwohl der std::shrared_mutex aus mehreren Threads (mithilfe des geeigneten Locks) gleichzeitig gesperrt werden kann (aber nicht aus dem gleichen Thread), kann ein std::recursive_mutex aus dem gleichen Thread mehrfach und gleichzeitig gesperrt werden (aber nicht aus unterschiedlichen Threads). Die Bilder unten zeigen es:
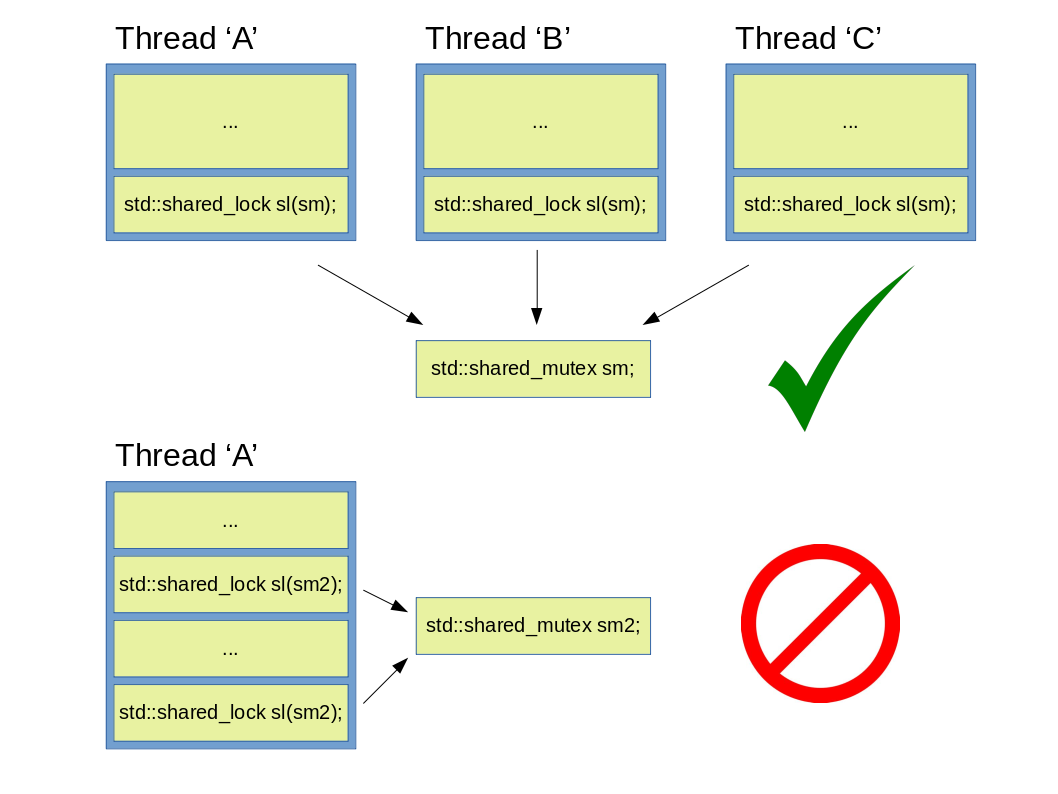 Abbildung 8: Korrekte und unsachgemäße Verwendung eines std::shared_mutex.
Abbildung 8: Korrekte und unsachgemäße Verwendung eines std::shared_mutex.
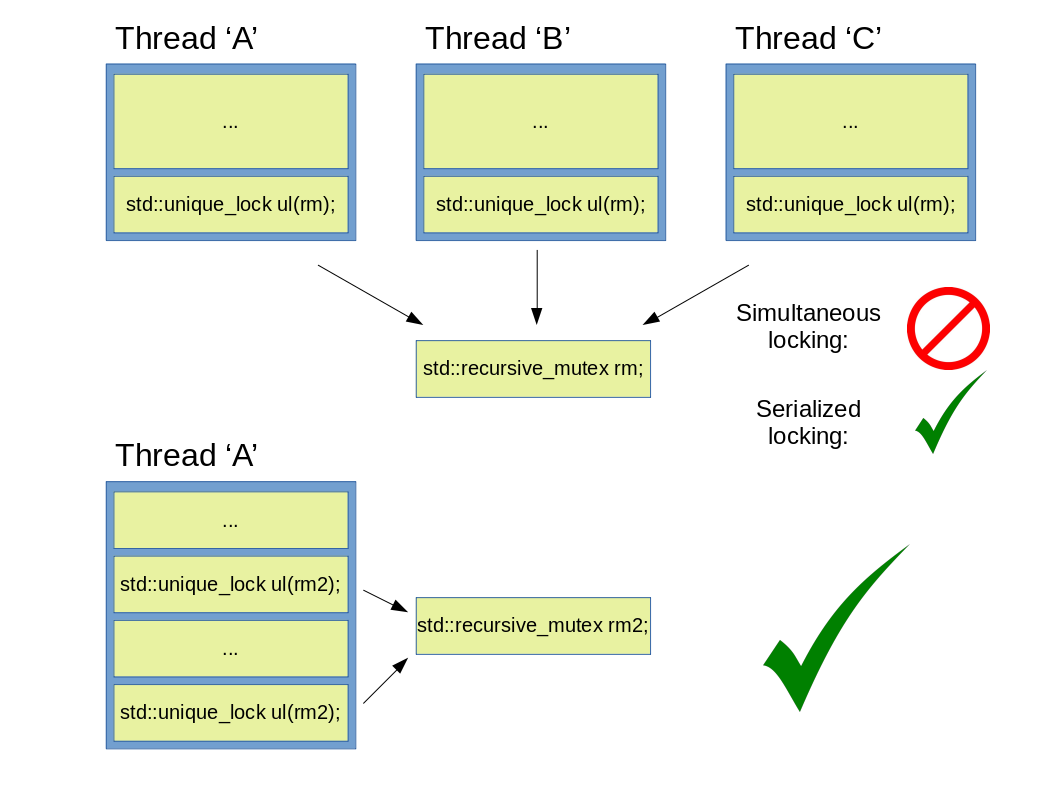 Abbildung 9: Korrekte und unsachgemäße Verwendung eines std::recursive_mutex.
Abbildung 9: Korrekte und unsachgemäße Verwendung eines std::recursive_mutex.
Das ist erwähnenswert, dass obwohl ein std::recursive_mutex (aus dem gleichen Thread) mehrfach gesperrt werden kann, wird das nicht durch einen std::shared_lock gemacht werden, sondern einen std::unique_lock oder ein std::lock_guard. Das ist wichtig, weil das gewährleistet, dass falls ein std::recursive_mutex aus mehreren Threads gesperrt würde, würde das nur auf eine klassische Weise gemacht werden: Thread ‘B’ kann Mutex rm nur dann sperren, wenn die Gesamtzahl der Entsperrungen in Thread ‘A’ die Zahl der Sperrungen gleicht:
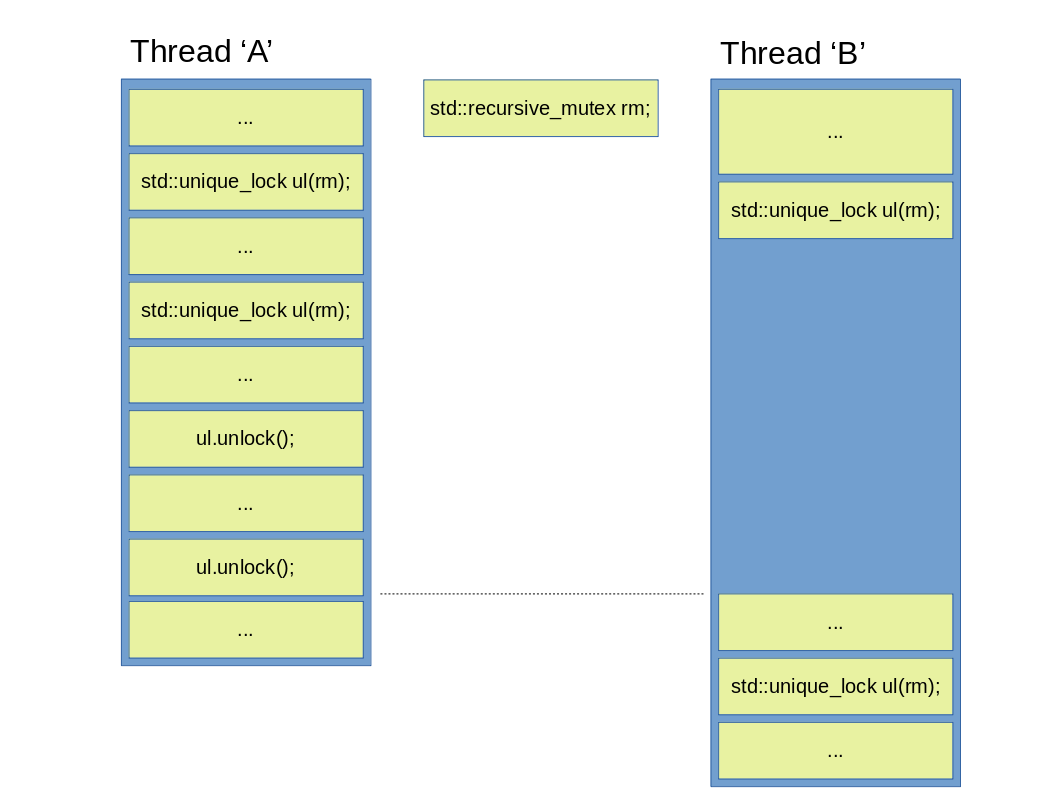 Abbildung 10: Einen std::recursive_mutex aus mehreren Threads verwenden.
Abbildung 10: Einen std::recursive_mutex aus mehreren Threads verwenden.
Man könnte jetzt die Frage stellen: wo sind solche Mutexe nutzbar? Laut Herrn Williams kann das für solche öffentlichen Klassenfunktionen verwendet werden, die eine andere öffentliche Klassenfunktion aufrufen, und beide müssen den Mutex sperren. Falls man den std::recursive_mutex benutzen will, ist das ein Zeichen eines schlechten Design, und deswegen ist die Nutzung dieses Mutexes (mal wieder, laut Herrn Williams) nicht empfohlen.
Ein anderer noch nicht diskutierter (aber schon erwähnter) Mutex ist std::timed_mutex, den man mithilfe der verschiedenen Sperrungsmöglichkeiten verstehen kann:
 Abbildung 11: In der C++17 Thread-Bibliothek vorhandene Mutexe und die dazugehörigen Sperrungsfunktionen.
Abbildung 11: In der C++17 Thread-Bibliothek vorhandene Mutexe und die dazugehörigen Sperrungsfunktionen.
Wie es offensichtlich ist, gibt es viele Methode für die Sperrung von Mutexen, aber nicht alle Mutexe unterstützen alle Sperrungsmethode. Also, was können alle diese Sperrfunktionen machen? Wie es der Name vermuten lässt, sperrt und entsperrt lock() und unlock() einen Mutex. Sie sind atomare Operationen, genauso wie alle andere Sperrfunktionen. Ein try_lock wird versuchen, den Mutex zu sperren, und abghängig von der Ergebnis wird es true oder flase zurückgeben.
try_lock_for und try_lock_until sind Locks, die in der C++ Chrono-Bibliothek definierte Zeitdauer und Zeitpunkt unterstützen. Bei try_lock_for() ist es möglich, eine Zeitdauer zu definieren, und während dieser Zeitdauer versucht der Lock einen Mutex zu entsperren. Falls innerhalb dieses Zeitraums gelingt dem Lock, den Mutex zu sperren, wird das true zurückgeben, sonst false. Ein try_lock_until() ähnelt sich sehr viel, aber in diesem Fall ist es möglich, einen zukünftigen Zeitpunkt einzustellen, bis dem der Lock die Sperrung versucht.
lock_shared(), try_lock_shared() und unlock_shared() funktionieren fast genau wie die nicht shared Gegenstücke, aber sie unterstützen einen geteilten Besitz (aus mehreren Threads gleichzeitig sperren).
Letztendlich gibt es try_lock_shared_for() und try_lock_shared_until(), die sich mal wieder den nicht shared Gegenstücken ähneln, bis auf die Unterstüztung der geteilten Sperrung.
Locks, mehrfache Sperrung der Mutexe, Deadlocks
An dieser Stelle könnte man wegen der unterschiedlichen Arten von Mutexe und Locks verwirrt sein, also das folgende Schaubild zeigt eine Sammlung der obengenannten Objekten (wie sie in der C++17 Standardbibliothek zur Verfügung stehen).
 Abbildung 12: Verschiedene Arten von Mutexen und Locks.
Abbildung 12: Verschiedene Arten von Mutexen und Locks.
Über die gezeigten Mutexe wurden schon diskutiert, aber die Locks hatten bisher nur eine kurze Einführung, also das ist an der Zeit, auch Locks darzustellen. Falls man die Namen der Locks untersucht, könnte man die folgende Frage stellen: was ist der Unterschied zwischen std::lock_guard und std::scoped_lock? Beide sind Locks ohne zusätzliche Funktionen, deswegen können sie nur für einfache Scopebewusste Sperrung verwendet werden. Also, warum braucht man beide? Die einfache Antwort ist, dass es Fälle geben können, in denen die Sperrung von mehreren Mutexe eine Anforderung ist, und es wäre toll, wenn es auf eine sichere Weise und mit der Vermeidung von Deadlocks getan werden könnte. Ein Beispiel für einen Deadlock ist unten zu sehen.
 Abbildung 13: Zwei Threads versuchen zwei Mutexe für exklusiven Zugang zu sperren. Eine klassiche Deadlock-Situation.
Abbildung 13: Zwei Threads versuchen zwei Mutexe für exklusiven Zugang zu sperren. Eine klassiche Deadlock-Situation.
Aus der Abbildung ist ersichtlich, dass beide Threads in einen Punkt der Ausführung angekommen sind, wo sie einen von dem anderen Thread besitzten Mutex sperren wollen, und deswegen werden beide Threads für immer warten. Man könnte behaupten, dass wenn man den Code umgestaltet, sodass die Locks so nah wie möglich gestellt werden, wird es bei diesem Problem helfen. Leider wird es solche Lösung dank der C++ Speicherverwaltungschemen die Vermeidung von Deadlocks nicht gewährleisten. Um solche Probleme komplett zu vermeiden, könnte std::scoped_lock anstatt des std::lock_guard verwendet werden, weil das die atomare Sperrung von mehreren Mutexen unterstützt:
 Abbildung 14: std::scoped_lock vermeidet Deadlocks.
Abbildung 14: std::scoped_lock vermeidet Deadlocks.
Andererseits, wenn die Sperrung von mehreren Mutexen nicht nötig ist, sondern die Sperrung/Entsperrung von Mutexen wichtiger ist, ohne den Lock zu zerstören, könnte ein std::unique_lock verwendet werden. Weiterhin ist ein std::unique_lock in der Lage, den Besitz ohne die Entsperrung des Mutexes zu entlassen. Der umgekehrte Fall ist auch möglich: sie können den Besitz des Mutexes erwerben, ohne es zu sperren. Diese Flexibilität ist dennoch nicht ohne Preis, weil die Information über den Besitz speichert und aktualisiert werden muss, also genauso wie bei allen anderen Bibliothekfunktionen soll man die zusätzlichen Laufzeit und Speicherkosten überlegen.
Ein shared_lock ähnelt sich dem vorigen Lock, aber der Unterschied ist, dass es einen std::shared_mutex (oder andere Mutexe, die die Voraussetzungen eines SharedMutexes erfüllen) sperren kann, indem das einen geteilten Besitz und Zugriff auch erlaubt.
Ich werde diesen Beitrag hier beenden, obwohl es andere Themen, die auch so interessant wie dies sind, gibt, aber weil dieses Beitrag schon zu lang ist, wäre es sinnlos fortzufahren. Interessenten sollten keine Angst haben, weil ein zweiter Teil dieses Themas schon geteilt ist, in dem über weitere Funktionalitäten der C++ Thread-Bibliothek diskutiert werden. Der Beitrag ist hier zu finden.
Wie immer, vielen Dank fürs Lesen.