- Intro
- C++ General threading
- Simple serialization
- Partial serialization
- Other mutexes and locking methods
- Locks, multiple mutex locking, deadlocks
Intro
Dear Readers!
This time I’m going to discuss a topic that touches one of the subjects that I truly care about in computing, performance. I guess this doesn’t come as a surprise to those who know a bit or more about C++, as more often than not, people who learn this particular language have this interest in common. Fortunately for all C++ enthusiasts, with the release of the C++11 standard the language got another boost in the already not so bad performance department, namely the official support of concurrency backed with an appropriate memory model and library facilities. If one reads this nice summary about the threading features of the current and upcoming standards, than it is apparent, that the topic itself didn’t loose relevance, but instead it is becomming ever more important with each release. Since many libraries use some sort of threading (even if it is self-implemented, like that of Qt) it is important to have an overview of the threading facilities, hence the writing of this post. So let’s get started.
DISCLAIMER: Since I’m also just learning about concurrency in general, many of the explanations will be very simple, layman-like to allow quick understanding of the library facilites. I’m not even going to try to touch details (or go into the very basics of threading for that matter), as there are excellent books on the subject, one of them being the very recently released 2nd edition “C++ Concurrency in Action” by Anthony Williams, which I’m also using as a basis for this post. Because of the existence of books and the enormity of the topic, I’ll restrict myself to discussing things directly related to the C++ threading library only, so some sort of prior knowledge is expected. For many more details and in-depth discussion on concurrency, please refer to that book (or any other you wish).
Also, if you happen to find some errors, mistakes, or simply have a suggestion, please feel free to let me know. All input is welcome.
C++ General threading
One of C++’s easier to understand threading facilities is std::thread. One can think of it as a container object for threads, which can only hold one single thread at a time. Being an object, all the usual properties of other objects apply to it equally, like lifetime, movability, member functions, internal state, etc, so basically it doesn’t need any more special treatment than a std::vector object for example. Let’s see it in action:
 Figure 1: A main thread launches two child threads, than waits for both of them.
Figure 1: A main thread launches two child threads, than waits for both of them.
In this example the main thread launches two separate threads, t1 and t2, after which it continues to do its stuff until a join() function is called on both of them. These functions are points in the program, where the main thread will rejoin with all previously launched threads (hence the name), which means, that calling a join() for each launched thread is absolutely necessary at one point or another. Observant readers probably also noticed, that there is a gap between the join()s of the extra threads, and this is not by accident. This depicts a very important property of the join() function: if a launched thread (Thread #3) ends its work only after the parent thread has finished its own work (that was stacked up until the call for join() ), the parent thread will wait (and essentially do nothing) until the child finishes. If, on the other hand the child (Thread #2) finishes before the call for its own corresponding join(), the parent will continue processing as usual. Of course, this sort of thread control may not always be suitable, so a different approach is also available, as depicted below:
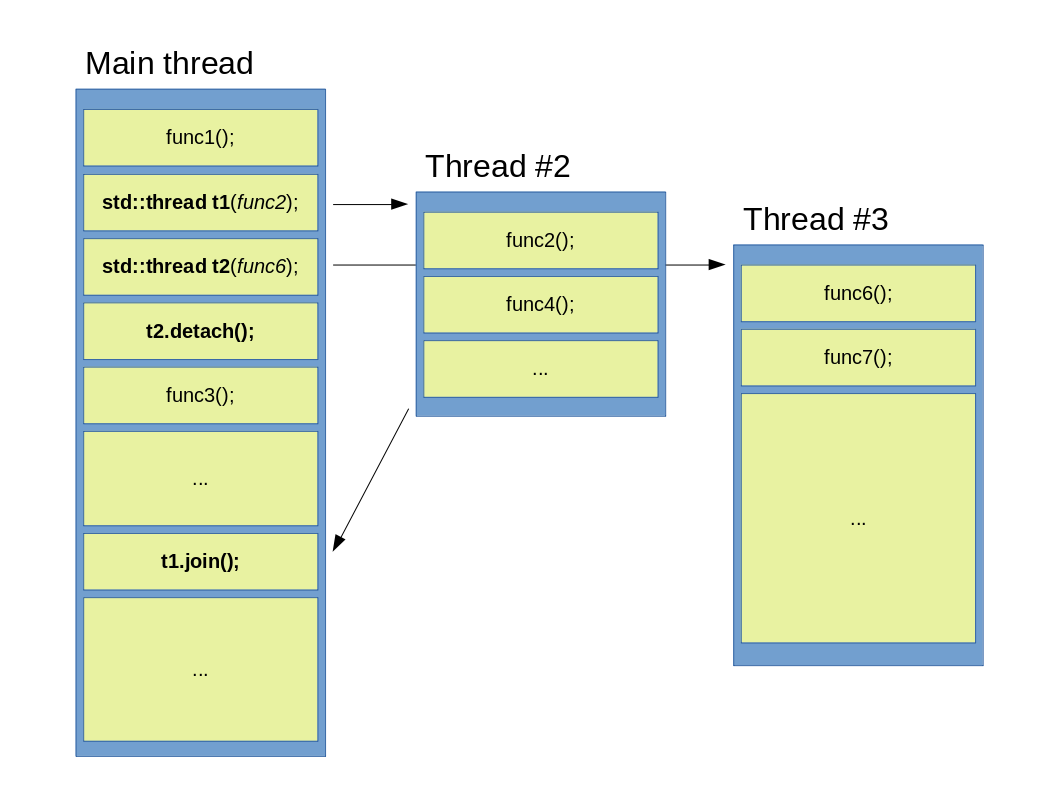 Figure 2: A main thread launches two child threads, then waits only for one of them.
Figure 2: A main thread launches two child threads, then waits only for one of them.
This example illustrates a different scenario. The main thread still launches two children, but after t2 has been created, a detach() is called upon it immediately. Calling a detach basically means, that the parent thread doesn’t concern itself anymore what the child does, and from that point on t2 has its own separate life. This is depicted above with a lack of a gap between tasks and the absence of an arrow pointing back to the main thread. An important distiction here is that while a normal thread is owned and controlled by the parent through a std::thread object, the ownership and control of a detached thread is transferred to the C++ runtime library, which transfer is irreversible. This means that once a thread has been detached, there is no way to reclaim it and the std::thread object it was associated to can now be considered as empty and ready for reuse or destruction. If a std::thread object is associated to an actual thread, it can be checked with a call to joinable(). Such detached threads are also known as deamon threads.
Simple serialization
There are many situations when launching completely isolated separate threads is not an option, but state needs to be shared between them. Such sharing of mutable data between them can be problematic because of data races and the following undefined behavior, so the C++ Thread Library defines several types to help facilitate safe access to such data. Take special note of the word ‘mutable’ here, as simultaneous access on read-only data does not usually generate any ill effects. Probably the most general solution of the existing protection facilities is the std::mutex, which can be thought of as a special type of bool, that also has two states only: locked and not locked. The biggest difference (but not the only one) between and ordinary bool and a mutex is, that only one thread can lock it (aka. change its state) at a time, which means that any other thread calling a lock() on a particular mutex while it is locked (it is in the true state), will have to wait until it gets unlocked (set back to false). Locking a mutex is also an atomic operation, which means that viewing the process from the outside world (aka. other threads), a change in the mutex’s state is instantaneous, or in other words, intermediate (invariant breaking) states are not possible.
The main purpose of a mutex is to block access to code (and as such data stored in variables) for threads that did not lock the mutex, which in turn insures that the protected code is only executed by a single thread at a time (see figure below).
 Figure 3: A mutex blocking simultaneous execution of protected code.
Figure 3: A mutex blocking simultaneous execution of protected code.
As it is clearly seen above, thread ‘A’ locks the mutex, after which it immediately can start executing the protected code. Threads ‘B’ and ‘C’ call the lock() function some time after ‘A’, but since the mutex is already locked by ‘A’, these two threads have to wait until thread ‘A’ calls unlock(). After mutex m has been unlocked, ‘B’ locks it and does the work on the same protected area that ‘A’ previously worked on, then finally unlocks it to allow thread ‘C’ to proceed. Because only one thread can work with the protected code at any single time and all the other threads can work on it in succession only, this procedure is also called serialization, as no parallel executions can happen at that place. One can visualize it in different ways, two of which is depicted below. The first one depicts two bottles connected at their necks, where in the neck we find our mutex protected code and only serial execution of it can happen.
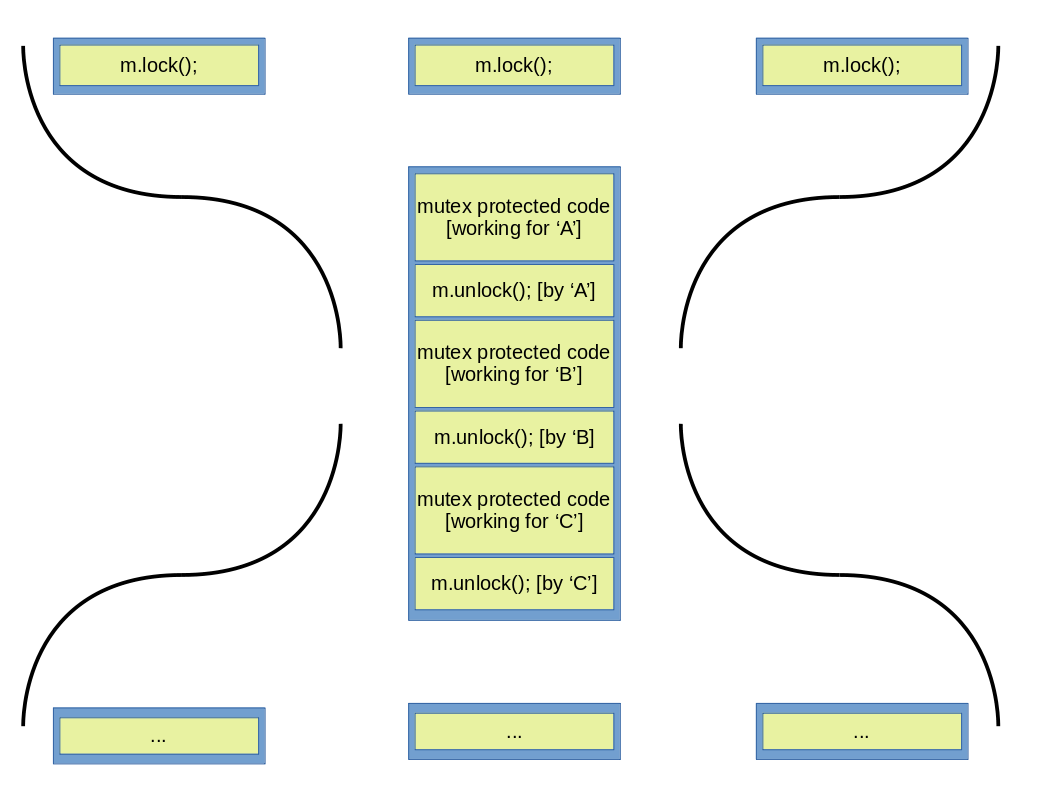 Figure 4: Serialization depicted using the ‘connected bottle’ scheme.
Figure 4: Serialization depicted using the ‘connected bottle’ scheme.
The second one shows a ‘virtual serialization thread’ being launched, which doesn’t allow any other thread to continue while the appropriate unlock function hasn’t been called in it. Remeber though, that no new thread is launched in reality, this is why it is called virtual.
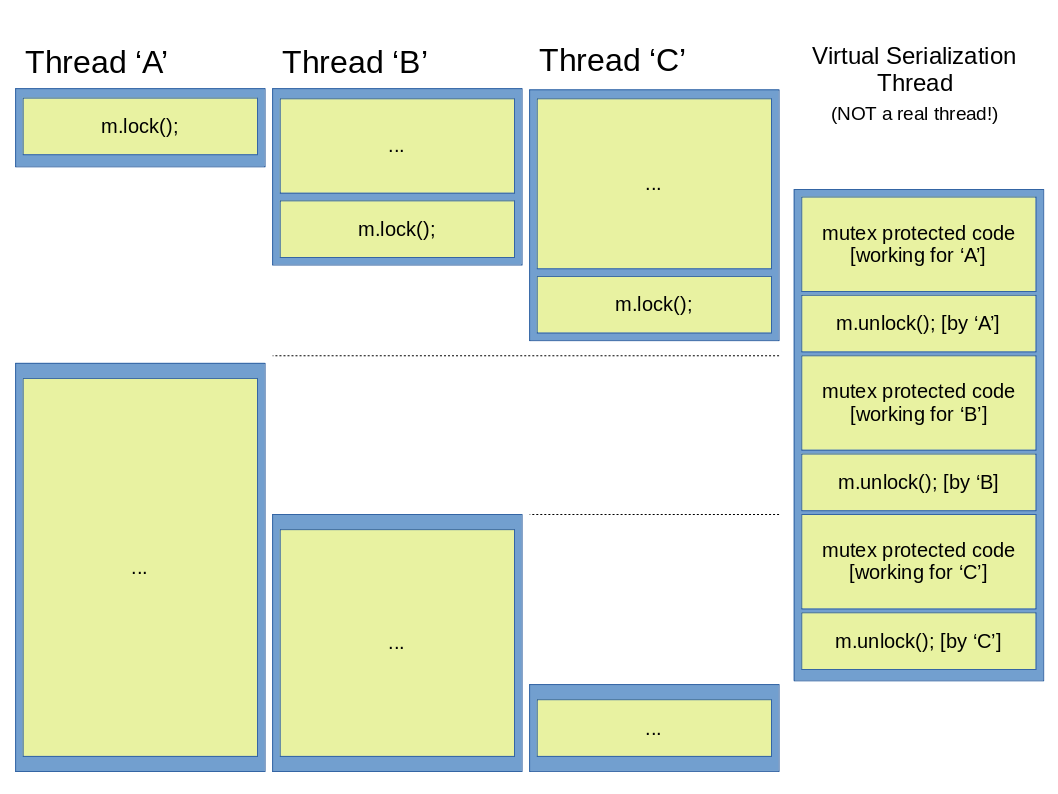 Figure 5: Serilaization depicted using the ‘virtual thread’ scheme.
Figure 5: Serilaization depicted using the ‘virtual thread’ scheme.
One must be aware however, that the figures above depict an oversimplified execution pattern, as in reality there is no guarantee that from the two waiting threads ‘B’ will be the one that locks the mutex before ‘C’, just because ‘B’ called the lock() function before the other. It is quite possible that ‘C’ will work on the protected code before ‘B’, even though it called lock() only after ‘B’, thanks to the C++ memory model and the various memory ordering schemes it supports (see aforementioned book for a great deal of detail on this).
Partial serialization
Of course, the above scheme can be too restrictive for some purposes, as it may very well be, that only thread ‘A’ wants to modify protected data, while threads ‘B’ and ‘C’ only want to read it, which, as discussed before, is allowed without any ill effects. This means that the delay seen for thread ‘C’ is entirely unnecessary under such circumstances, so an execution pattern as seen below would be much more favorable:
 Figure 6: A desired improved execution pattern if ‘B’ and ‘C’ only want to read data.
Figure 6: A desired improved execution pattern if ‘B’ and ‘C’ only want to read data.
This execution pattern could be called partial serialization, because serialization doesn’t happen under all circumstances, but only at some desired ones. As it turnes out, it is achievable by using mutexes that offer more functionality than a plain std::mutex. For example a std::shared_mutex or a std::shared_timed_mutex used in concert with std::unique_lock and std::shared_lock can do exactly what we need, but before going into specifics, there are a few things that need mentioning. One of them being is the similar nature of mutexes to using the new operator and raw pointers to create new objects. In both cases the programmer is responsible for housekeeping, which means that once the lock() function has been called on a mutex, the programmer must ensure that unlock() is also called later in the code, or other threads will be blocked indefinitely. This is similar to the need to call delete after an object has been created with a plain new, otherwise there would be memory leaks. Similarities don’t end here, as calling lock() and unlock() more than once on a std::mutex from within the same thread will result in undefined behavior, just the same as calling delete twice on a pointer pointing to an object on the heap.
 Figure 7: Similarities between new/delete and lock()/unlock()
Figure 7: Similarities between new/delete and lock()/unlock()
To avoid the aforementioned problems, the RAII idiom can be employed (again, just the same as for new/delete), but for mutexes through the use of lock guards, such as std::lock_guard. The purpose of lock guards is to ensure a scope lifetime of the locking/unlocking, which means that when the lock guard goes out of scope, it will unlock the mutex through its destructor. This not only ensures limited (and automatic) lifetime for the locking, but also avoids trying to lock/unlock the mutex multiple times.
After having a short description of locks, let’s get back to the improved execution pattern of Figure 6. By using a std::shared_mutex or a std::shared_timed_mutex, both of which differ from a plain std::mutex in that they can be locked multiple times if used in concert with appropriate locks (e.g. std::lock_guard / std::unique_lock and std::shared_lock), one can create a so called reader-writer mutex. If a shared mutex is locked with an instance of e.g. std::unique_lock, then the thread using such a lock will have exclusive access to the protected code, and as such no parallel executions are possible. This is needed when the invariants of the protected area is needed to be broken temporarily (e.g. when adding a new element to a data structure). If no invariants are to be broken by our operation on the other hand (e.g. reading), then a std::shared_lock can be used, as this type of lock allows multiple threads to lock a mutex supporting multilple locking, which will in turn allow multiple threads to access the protected code (and make true concurrency possible). It is important to note here, that regardless of the mutex used, a std::unique_lock or std::lock_guard doesn’t allow a mutex to be locked from multilple threads, and as such as long as any std::shared_lock is using a mutex (that can be locked multilple times), it will not lock it.
Other mutexes and locking methods
One of the mutexes that hasn’t been mentioned before is the std::recursive_mutex, which can be thought of as the complete opposite of a std::shrared_mutex: while the shared mutex can be locked from multiple threads in the same time (with an appropriate lock), but not from within the same thread; a std::recursive_mutex on the other hand can be locked multiple times from the same thread, but not from different ones (simultaneously anyway). See images below:
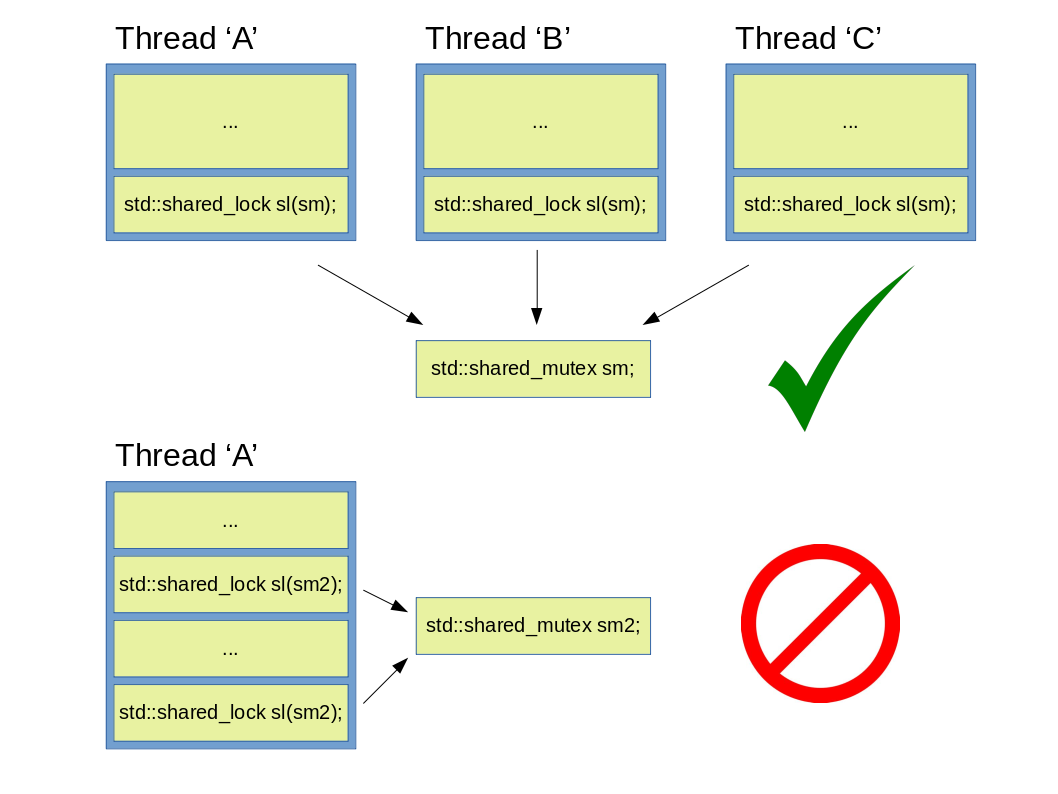 Figure 8: Valid and incorrect usage of a std::shared_mutex.
Figure 8: Valid and incorrect usage of a std::shared_mutex.
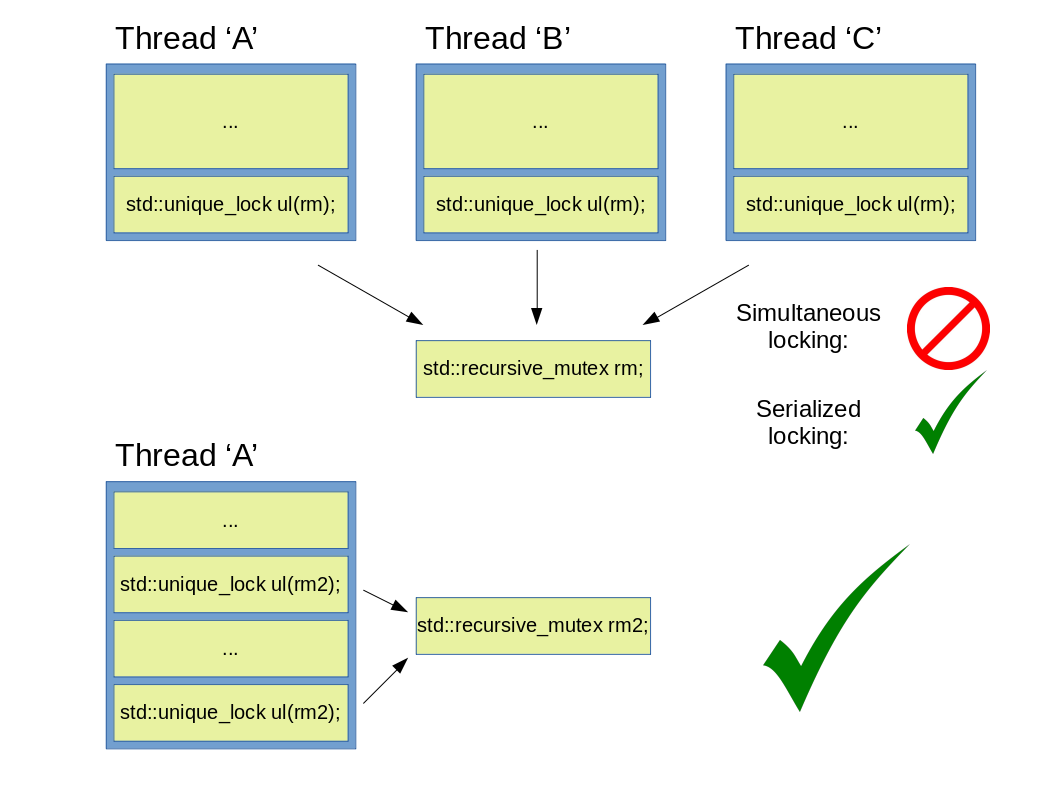 Figure 9: Valid and incorrect usage of a std::recursive_mutex.
Figure 9: Valid and incorrect usage of a std::recursive_mutex.
It is noteworthy to mention, that although a std::recursive_mutex can be locked multiple times (from the same thread), contrary to intuition, it is not done by a std::shared_lock, but instead with a std::unique_lock or a std::lock_guard. This is important, because this pretty much guarantees that even if a recursive mutex is to be locked from multiple threads, it will be done in the classical serial manner only, aka: thread ‘B’ will only be able to lock mutex rm, if it has been unlocked in advance as many times in thread ‘A’, as it has been locked. See below:
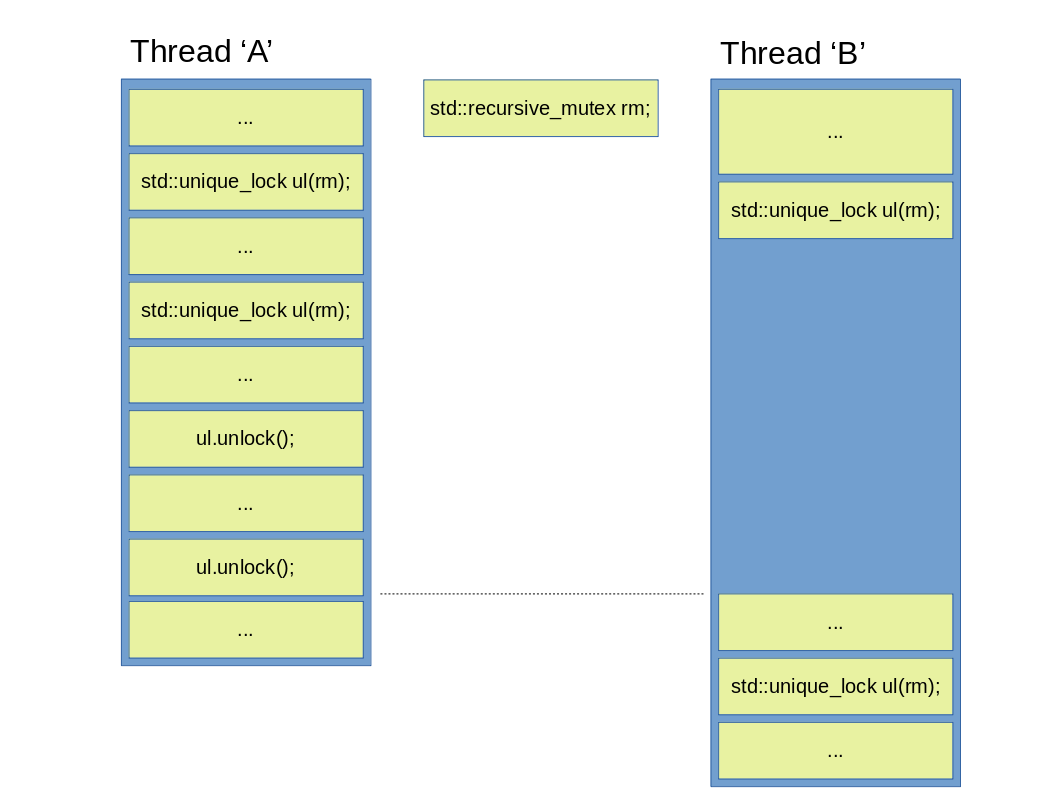 Figure 10: Using a std::recursive_mutex from multiple threads.
Figure 10: Using a std::recursive_mutex from multiple threads.
So, one might wonder where such a mutex could be useful? Well, according to Mr. Williams it can be used when a public member function of a class calls another public member function, where both of them need to lock the mutex. If one is considering to use a recursive mutex though, is a sign of bad design and as such it is not really recommended to be used (again, as described by Mr. Williams).
Another type of mutex that hasn’t been discussed (but occured already in some form), is the std::timed_mutex, which can be understood through the various ways a mutex can be locked, so let’s see:
 Figure 11: Mutexes available in the C++17 Thread Library and their corresponding locking functions.
Figure 11: Mutexes available in the C++17 Thread Library and their corresponding locking functions.
As it is evident from the image above, there are many ways to lock mutexes, but not all mutexes support all locking methods. So what those individual locking funtions can do? lock() and unlock() as the names suggest simply lock and unlock the mutex, respctively, which are atomic operations, just the same as all other lock functions. try_lock() will try to lock the mutex, and depending on success of failure to do so will return true or false.
try_lock_for() and try_lock_until() are locks supporting duration and time point (as defined in the C++ Chrono library), respectively. For try_lock_for() one can specify a duration of time, for which time the lock will try locking. If within the timeframe the lock was aquired, it will return true, otherwise false. A try_lock_until() is very similar, but this time one can specify a time point in the future, until the lock will try locking.
lock_shared(), try_lock_shared() and unlock_shared() work almost exactly like their non-shared counterparts, except that these support shared ownership (aka. locking from multiple threads simultaneously).
Finally there is try_lock_shared_for() and try_lock_shared_until(), which are again, almost the same as their non-shared counterparts except for the support of shared locking.
Locks, multiple mutex locking, deadlocks
At this point one might start to become confused about the different type of mutexes and locks, so the following figure shows a collection of those (as they are available in C++17).
 Figure 12: Various types of mutexes and locks.
Figure 12: Various types of mutexes and locks.
From the image above the various mutexes have already been discussed, but the locks only got a short intro so far, thus a one-by-one description is already owed at this point. By examining the names of various locks, one might wonder what could possibly be the difference between a std::lock_guard and a std::scoped_lock. Both of them are locks without any additional member functions, thus both of them can only be used for simple scope duration locking, so why have them both? The answer is because there might be situations when locking multiple mutexes is a requirement, and it would be nice if it could be done in a safe manner, where safe means avoiding deadlocks. An example of a deadlock can be seen below.
 Figure 13: Two threads trying to lock two mutexes for exclusive access. A classical deadlock situation.
Figure 13: Two threads trying to lock two mutexes for exclusive access. A classical deadlock situation.
As it is seen above, both threads arrived to a point in execution, where they would need to acquire a mutex that is already owned by the other to be able to continue, so both of them will be waiting forever. One might think that rearranging the code to put lock guards as close to each other as possible (aka. acquire the second mutex immediately after the first) might help, but even that would not guarantee that a deadlock would be avoided, again, thanks to the C++ memory ordering schemes. To avoid such problems altogether, the std::scoped_lock can be used instead of a std::lock_guard, as it supports atomic locking of multiple mutexes:
 Figure 14: std::scoped_lock preventing deadlocks.
Figure 14: std::scoped_lock preventing deadlocks.
On the other hand, if no locking of multilple mutexes is required, but instead the ability to lock/unlock mutexes wihtout destroying the lock itself, then a std::unique_lock can be employed. Not only that, but a unique lock is also capable of releasing ownership of the mutex without unlocking it first, and the opposite it also possible: they can acquire a mutex without locking it. All this flexibility is not without a price though, as information about ownership has to be stored and updated, so as with many other library facilities, careful consideration is required to determine if the additional runtime and storage costs are warranted.
A std::shared_lock is very similar to the previous one in function, but the difference is, that it can only lock a std::shared_mutex (or any mutex that meets the SharedMutex requirement, as defined in the standard), and it does so while allowing shared ownership and access.
I will end this post here, although there are other topics that would be equally interesting to discuss, like the various memory ordering schemes I referred to several times, but since this post already grew too long, there is no point in continuing. Interested readers shouldn’t dispair however, as a second part on this topic has been posted, where further facilities of the C++ thread library are discussed, which you can find here.
As always, thanks for reading.